Q: Anaytical model: A: To create an analytical model for energy-efficient CUDA kernel execution, you need to incorporate both hardware architecture knowledge and CUDA kernel behavior. Here’s how you can approach this:
1. Model Components
1.1. Hardware Architecture Knowledge
- Streaming Multiprocessors (SMs):
- Number of SMs on the GPU.
- Maximum active threads per SM.
- Shared memory and register file size per SM.
- Warp Scheduling:
- Warp size (32 threads).
- Latency hiding through warp scheduling.
- Power Characteristics:
- Static power () — baseline power consumption when idle.
- Dynamic power () — power consumed during kernel execution.
1.2. CUDA Kernel Behavior
- Thread Utilization:
- Number of active threads ().
- Occupancy — ratio of active warps to maximum warps per SM.
- Memory Access Patterns:
- Global memory bandwidth usage.
- Shared memory usage.
- Instruction Mix:
- Ratio of compute-bound vs memory-bound operations.
2. Analytical Model Formulation
2.1. Execution Time ()
Execution time depends on:
- Parallelism: Number of active threads and blocks.
- Memory Latency: Time spent waiting for memory operations.
Where:
- : Total number of operations in the kernel.
- : Total number of threads launched.
- : Memory latency component.
2.2. Power Consumption ()
Power consumption is the sum of static and dynamic power:
Dynamic power depends on:
- Active threads ().
- Memory bandwidth usage ().
- Compute intensity ().
Where are hardware-specific coefficients derived from profiling.
2.3. Energy Consumption ()
Energy is the product of power and execution time:
3. Optimization Objective
The goal is to minimize energy consumption by tuning:
- ThreadsPerBlock ().
- BlocksPerGrid ().
This involves solving:
4. Steps to Build the Model
Step 1: Profile the GPU
Use tools like NVIDIA Nsight or NVML to gather:
- Static and dynamic power values.
- Execution time for different configurations.
- Memory bandwidth and occupancy data.
Step 2: Derive Coefficients
Fit empirical data to derive coefficients for:
- in the dynamic power equation.
- Memory latency model parameters.
Step 3: Implement the Model
Write a function that predicts based on:
- GPU architecture parameters (e.g., max threads per block).
- Kernel characteristics (e.g., memory intensity).
Step 4: Solve for Optimal Configuration
Use numerical optimization techniques (e.g., grid search or gradient descent) to find the best and .
5. Example Model
def energy_model(TPB, BPG, N_ops, mem_intensity, gpu_params):
# Extract GPU parameters
P_static = gpu_params["P_static"]
k1, k2, k3 = gpu_params["k1"], gpu_params["k2"], gpu_params["k3"]
max_threads_per_block = gpu_params["max_threads_per_block"]
# Ensure valid configuration
if TPB > max_threads_per_block:
return float('inf') # Invalid configuration
# Calculate execution time
T_exec = N_ops / (TPB * BPG * gpu_params["instruction_throughput"]) + mem_intensity * gpu_params["memory_latency"]
# Calculate dynamic power
P_dynamic = k1 * TPB * BPG + k2 * mem_intensity + k3 * (N_ops / T_exec)
# Total power and energy
P_total = P_static + P_dynamic
E_total = P_total * T_exec
return E_total
# Example GPU parameters
gpu_params = {
"P_static": 20, # Static power in watts
"k1": 0.01, # Coefficient for active threads
"k2": 0.05, # Coefficient for memory bandwidth
"k3": 0.02, # Coefficient for compute intensity
"max_threads_per_block": 1024,
"instruction_throughput": 10**9,
"memory_latency": 10**-6,
}
# Example kernel parameters
N_ops = 10**8 # Total operations
mem_intensity = 0.5
# Optimize TPB and BPG
optimal_energy = float('inf')
optimal_config = None
for TPB in range(32, gpu_params["max_threads_per_block"]+1, 32):
for BPG in range(1, 1000):
energy = energy_model(TPB, BPG, N_ops, mem_intensity, gpu_params)
if energy < optimal_energy:
optimal_energy = energy
optimal_config = (TPB, BPG)
print(f"Optimal Configuration: ThreadsPerBlock={optimal_config[0]}, BlocksPerGrid={optimal_config[1]}")
print(f"Minimum Energy Consumption: {optimal_energy:.2f} Joules")6. Validation
Validate your analytical model by comparing its predictions with real-world measurements using CUDA profiling tools.
This approach ensures that your model incorporates both hardware constraints and kernel-specific behavior while optimizing for energy efficiency.
Q: # How are cuda applications run for large scale system on infrastructure level like high performance computing devices. what’s the tech stack used there. I am creating a cuda profiler that can work at infrastructure level and hence want the different tech stack and technologies used for running and executing large scale cuda application Answer: To run CUDA applications at scale on high-performance computing (HPC) infrastructure, several technologies and components are used in the tech stack. Here’s an overview of the key elements:
Hardware Infrastructure
- GPU Clusters: Large-scale CUDA applications typically run on clusters of GPU-equipped nodes[5].
- High-Speed Interconnects: Technologies like InfiniBand or NVIDIA NVLink are used for fast inter-node communication[5].
Software Stack
Operating System
- Linux distributions optimized for HPC, such as CentOS, Red Hat Enterprise Linux, or Ubuntu Server.
GPU Drivers and Runtime
- NVIDIA GPU drivers
- CUDA Toolkit, including the CUDA runtime
Job Scheduling and Resource Management
- Workload managers like Slurm, PBS, or IBM Spectrum LSF to allocate resources and manage job queues[1].
Parallel Computing Frameworks
- MPI (Message Passing Interface): For distributed memory parallelism across nodes[1].
- NCCL (NVIDIA Collective Communications Library): Optimizes multi-GPU and multi-node collective communication[5].
- NVSHMEM: Creates a global address space for data spanning multiple GPUs[5].
Development Tools
- NVIDIA HPC SDK: Includes compilers, libraries, and tools for GPU-accelerated HPC development[1][5].
- PGI Compilers: For GPU-accelerated Fortran, C, and C++ development.
Libraries and Frameworks
- cuBLAS, cuSOLVER, cuFFT, cuSPARSE: GPU-accelerated math libraries[1].
- PyTorch, TensorFlow: Deep learning frameworks with CUDA support[4].
Containerization
- Docker or Singularity: For portable and reproducible software environments[1].
- NVIDIA Container Runtime: Enables GPU support in container frameworks[1].
Profiling and Debugging Tools
- NVIDIA Nsight Systems: For system-wide performance analysis[1].
- NVIDIA Nsight Compute: For in-depth GPU kernel profiling[1].
- CUDA-GDB: For debugging CUDA applications.
File Systems
- Parallel file systems like Lustre or GPFS for high-performance I/O.
Execution Flow
- Users submit CUDA jobs to the workload manager.
- The workload manager allocates resources (GPUs, CPUs, memory) across the cluster.
- The job is launched on the allocated nodes, often using MPI for multi-node execution.
- CUDA kernels are executed on the GPUs, with inter-GPU communication handled by libraries like NCCL.
- Results are collected and stored, often on a parallel file system.
Profiling Considerations
For a CUDA profiler working at the infrastructure level, you’ll need to consider:
- Integration with job schedulers to capture job-level metrics.
- Ability to aggregate data from multiple nodes and GPUs.
- Low-overhead data collection to minimize impact on running applications.
- Support for various CUDA versions and GPU architectures.
- Integration with existing HPC monitoring tools and dashboards.
By understanding this tech stack, you can design your CUDA profiler to interface effectively with the various components of an HPC system, providing valuable insights into large-scale CUDA application performance across the entire infrastructure.
Citations: [1] https://developer.nvidia.com/hpc-sdk [2] https://developer.nvidia.com/hpc [3] https://www.lumi-supercomputer.eu/preparing-codes-for-lumi-converting-cuda-applications-to-hip/ [4] https://www.hpcwire.com/2024/06/21/spelunking-the-hpc-and-ai-gpu-software-stacks/ [5] https://developer.nvidia.com/blog/fueling-high-performance-computing-with-full-stack-innovation/ [6] https://www.amax.com/the-power-of-gpu-clusters-unleashing-high-performance-computing/ [7] https://developer.nvidia.com/deep-learning-software
Question: I want to create a plug-in or tool using which i want to change the power limit of GPU’s in runtime while the Cuda application is executing, which part of the Execution Flow should i make the tool for? Answer: To create a plugin or tool that can change the power limit of GPUs in runtime while a CUDA application is executing, you should focus on integrating with the GPU driver and resource management layer of the execution flow. Here’s how you can approach this:
Integration Point
Your tool should interface with the NVIDIA GPU driver and the NVIDIA Management Library (NVML). This allows you to modify GPU settings without interrupting the running CUDA application.
Key Components
-
NVIDIA Management Library (NVML): This is the primary API you’ll use to interact with and control NVIDIA GPUs[3].
-
nvidia-smi: While not directly used in your tool, understanding how nvidia-smi works can provide insights into GPU management[3].
-
Driver Persistence Mode: Ensure this is enabled to maintain settings across reboots[3].
Implementation Approach
-
Dynamic Library Loading: Create a shared library that can be loaded by the CUDA application at runtime.
-
NVML Integration: Use NVML functions to query and set GPU power limits.
-
Interprocess Communication: Implement a mechanism for your tool to communicate with the running CUDA application.
Code Outline
Here’s a basic outline of how your tool might function:
#include <nvml.h>
// Initialize NVML
nvmlInit();
// Get handle to the GPU
nvmlDevice_t device;
nvmlDeviceGetHandleByIndex(0, &device);
// Set new power limit (in milliwatts)
unsigned int newPowerLimit = 300000; // 300W
nvmlDeviceSetPowerManagementLimit(device, newPowerLimit);
// Clean up
nvmlShutdown();Considerations
-
Performance Impact: Changing power limits during runtime may affect application performance. Monitor and profile the application to understand the impact[1].
-
Thermal Management: Adjusting power limits can affect GPU temperatures. Implement safeguards to prevent overheating[1].
-
Multi-GPU Systems: If working with multiple GPUs, ensure your tool can handle and individually control each GPU[3].
-
Error Handling: Implement robust error handling to manage scenarios where power limit changes fail or are not supported.
-
User Interface: Consider creating a simple UI or command-line interface for real-time control.
-
Persistence: Implement a method to persist changes across reboots if desired, possibly using a systemd service[3].
By focusing on these aspects, you can create a tool that integrates seamlessly with the GPU management layer, allowing for dynamic power limit adjustments during CUDA application execution. This approach provides flexibility in managing GPU power consumption without interrupting the running application, which can be crucial for optimizing performance and energy efficiency in high-performance computing environments.
Citations: [1] https://www.pugetsystems.com/labs/hpc/update-v0-2-nvidia-gpu-powerlimit-setup-2352/ [2] https://massedcompute.com/faq-answers/?question=How+do+I+monitor+and+control+power+consumption+of+NVIDIA+data+center+GPUs+using+CUDA+GPU+settings%3F [3] https://gist.github.com/jctosta/b968a6edc592ad7d06d9c91bd0796024 [4] https://forums.developer.nvidia.com/t/limit-sm-speed/259615 [5] https://www.amax.com/the-power-of-gpu-clusters-unleashing-high-performance-computing/ [6] https://linuxconfig.org/how-to-set-nvidia-power-limit-on-ubuntu [7] https://github.com/Emanem/nv-pwr-ctrl [8] https://www.techpowerup.com/forums/threads/feature-request-enable-power-limit-slider-for-mobile-gpu-like-driver-528-24.310787/ [9] https://www.sciencedirect.com/science/article/abs/pii/S0167739X23001267
Question: Let’s say, for example, a company works on running large-scale CUDA applications on GPU clusters. How should i design my tool so that it’s easier, comfortable and safe for them to use it in their execution workflow. Answer: To design a tool for changing GPU power limits in runtime that is easy, comfortable, and safe for companies running large-scale CUDA applications on GPU clusters, you should consider the following aspects:
Integration with Existing Infrastructure
-
Cluster Management Compatibility: Ensure your tool is compatible with popular cluster management systems like Slurm or PBS[1].
-
Containerization Support: Make your tool compatible with containerized environments such as Docker or Singularity, which are commonly used in HPC settings[1].
User Interface and Control
-
Command-Line Interface (CLI): Provide a robust CLI for easy integration with existing scripts and workflows.
-
Web-based Dashboard: Offer a web interface for real-time monitoring and control, accessible from the head node.
-
API: Develop a RESTful API to allow programmatic control and integration with custom workflows.
Safety and Performance Features
-
Thermal Management: Implement safeguards to prevent overheating when adjusting power limits.
-
Performance Monitoring: Integrate with tools like NVIDIA Nsight Systems to correlate power changes with application performance[5].
-
Rollback Mechanism: Include an automatic rollback feature if power limit changes negatively impact performance or stability.
-
Logging and Auditing: Implement comprehensive logging for all power limit changes and their effects.
Scalability and Flexibility
-
Multi-GPU Support: Design the tool to handle multiple GPUs across numerous nodes efficiently.
-
Customizable Policies: Allow users to define policies for automatic power limit adjustments based on workload characteristics.
-
Cluster-wide Management: Provide options for managing power limits across the entire cluster or specific node groups.
Ease of Deployment
-
Minimal Dependencies: Design the tool with minimal external dependencies to simplify installation and maintenance.
-
Configuration Management: Support configuration through files (e.g., YAML) for easy deployment and version control.
-
Integration with Existing Monitoring: Allow integration with cluster monitoring tools for unified system oversight.
Security Considerations
-
Access Control: Implement role-based access control to restrict who can modify power settings.
-
Secure Communication: Use encrypted communications for all control operations, especially in multi-user environments.
-
Audit Trail: Maintain a secure, tamper-evident log of all power limit changes and user actions.
Workflow Integration
-
Job Scheduler Hooks: Provide hooks for job schedulers to adjust power limits automatically at job start/end.
-
Application Profiling Integration: Allow the tool to adjust power limits based on application profiling data, potentially integrating with NVIDIA Nsight Compute[5].
-
Energy Optimization: Implement features to optimize energy usage across the cluster based on workload distribution.
Example Workflow Integration
Here’s how your tool might integrate into a typical HPC workflow:
- User submits a CUDA job through the cluster’s job scheduler.
- Before job execution, your tool reads job-specific power policies.
- As the job starts, your tool sets initial power limits for allocated GPUs.
- During execution, your tool monitors performance and thermal data.
- Based on predefined policies or real-time analysis, your tool adjusts power limits dynamically.
- If performance degrades, your tool can revert changes or alert administrators.
- Upon job completion, your tool resets GPUs to default power settings.
- All actions are logged for later analysis and optimization.
By focusing on these aspects, you can create a tool that seamlessly integrates into existing HPC workflows, provides powerful control over GPU power management, and ensures safe and efficient operation of large-scale CUDA applications on GPU clusters.
Citations: [1] https://centml.ai/guide-gpu-clusters/ [2] https://research.aimultiple.com/gpu-cluster/ [3] https://dl.acm.org/doi/abs/10.1145/3372790 [4] https://docs.nvidia.com/cuda/cuda-c-best-practices-guide/index.html [5] https://www.youtube.com/watch?v=dB5Jxwj0PDw [6] https://www.amax.com/the-power-of-gpu-clusters-unleashing-high-performance-computing/ [7] https://www.hpcwire.com/2024/06/21/spelunking-the-hpc-and-ai-gpu-software-stacks/
Question: Suppose you are a large company that runs large-scale Cuda applications on GPU clusters. Develop an example scenario and complete execution workflow using my tool that changes the power limit of GPU in runtime while a Cuda application is running to save energy. This should include tech stack and how my tool would be installed, setup and plugged in the current execution workflow. Answer: Let’s consider a scenario for a large pharmaceutical company, PharmaTech, that runs complex molecular dynamics simulations using CUDA on their GPU cluster. They want to optimize energy usage without compromising performance. Here’s how they might integrate your GPU power limit tool into their workflow:
Scenario: PharmaTech’s Molecular Dynamics Simulation
PharmaTech runs week-long simulations of protein folding on their 1000-node GPU cluster, each node equipped with 4 NVIDIA A100 GPUs. They want to reduce energy consumption during less computationally intensive phases of the simulation.
Tech Stack
- Hardware: 1000 nodes, each with 4 NVIDIA A100 GPUs
- OS: CentOS 8 Stream
- Job Scheduler: Slurm
- Container Platform: Singularity
- CUDA Version: CUDA 11.5
- Application: GROMACS (GPU-accelerated molecular dynamics software)
- Monitoring: Grafana with Prometheus
- File System: Lustre
Your Tool: DynaPower
Let’s call your tool “DynaPower”. Here’s how it would be integrated:
Installation and Setup
-
Installation:
wget https://dynapower.com/releases/dynapower-1.0.tar.gz tar -xzvf dynapower-1.0.tar.gz cd dynapower-1.0 ./configure --prefix=/opt/dynapower make && sudo make install -
Configuration: Create a configuration file
/etc/dynapower/config.yaml:global: default_power_limit: 300W min_power_limit: 200W max_power_limit: 400W policies: - name: gromacs_policy application: gromacs phases: - name: initialization power_limit: 250W - name: main_loop power_limit: 350W - name: analysis power_limit: 300W -
Integration with Slurm: Add to
/etc/slurm/epilog.d/dynapower:#!/bin/bash /opt/dynapower/bin/dynapower-reset
Execution Workflow
-
Job Submission: User submits a GROMACS job:
sbatch gromacs_job.sh -
Job Script (
gromacs_job.sh):#!/bin/bash #SBATCH --nodes=100 #SBATCH --gpus-per-node=4 #SBATCH --time=168:00:00 module load gromacs/2021.4-cuda11.5 module load dynapower/1.0 # Initialize DynaPower dynapower-init --policy gromacs_policy # Run GROMACS simulation srun gmx mdrun -s topol.tpr -deffnm md # Cleanup dynapower-cleanup -
Execution Flow:
- Slurm allocates 100 nodes with 4 GPUs each.
dynapower-initsets initial GPU power limits to 250W for the initialization phase.- GROMACS starts running the simulation.
- DynaPower monitors the application phase:
- During main computation loops, it increases power limit to 350W.
- During analysis phases, it reduces power limit to 300W.
- DynaPower continuously logs power usage and performance metrics.
-
Monitoring:
- Grafana dashboard shows real-time power usage and performance metrics.
- Administrators can manually adjust power limits if needed through the DynaPower web interface.
-
Job Completion:
dynapower-cleanupresets GPUs to default power settings.- Slurm epilog script ensures all GPUs are reset, even if the job terminates unexpectedly.
-
Post-Job Analysis:
- DynaPower generates a report of energy usage and performance impact.
- This data is used to refine power management policies for future jobs.
Benefits
- Energy savings during less intensive computation phases.
- Automatic adaptation to application needs without user intervention.
- Detailed monitoring and reporting for ongoing optimization.
- Seamless integration with existing HPC workflow and tools.
By integrating DynaPower in this manner, PharmaTech can optimize their GPU power usage based on the specific needs of their GROMACS simulations, potentially saving significant energy over the course of long-running jobs while maintaining performance where it’s most critical. The tool’s flexibility allows for easy adaptation to other CUDA applications in their portfolio as well.
Question: I want you to do a literature review if any tool like this already exists, and what are closest related works that I can use for literature review of my research work. Answer: Based on your request for a literature review on tools that can change GPU power limits at runtime for CUDA applications, I’ve analyzed the available search results and related research. While there isn’t a direct match for your specific tool, there are several related works and approaches that you can use for your literature review. Here’s a summary of relevant research and tools:
-
Program Analysis and Machine Learning-based Power Prediction: A 2023 paper titled “Program Analysis and Machine Learning–based Approach to Predict Power Consumption of CUDA Kernel” by Alavani et al. presents a method to predict GPU power consumption using program analysis[1]. While this doesn’t directly control power limits, it provides insights into power consumption prediction, which could be valuable for your research.
Key points:
- Uses machine learning to predict power consumption
- Achieves high accuracy (R² value of 0.9646 on Volta Architecture)
- Helps developers understand power consumption patterns in CUDA applications
-
NVIDIA System Management Interface (nvidia-smi): While not a research tool, nvidia-smi is widely used for monitoring and controlling NVIDIA GPUs, including power management[3]. It allows setting power limits, which is close to what your tool aims to achieve.
Key features:
- Can set and query power limits
- Provides real-time monitoring of GPU power consumption
- Can be used in scripts for automated power management
-
GPU Power Optimization Strategies: A presentation by Mark Harris from NVIDIA on “Optimizing CUDA” discusses various optimization strategies, including power efficiency[2]. While not a tool itself, it provides insights into how developers can optimize CUDA applications for better power efficiency.
Relevant topics:
- Optimizing memory access for power efficiency
- Utilizing on-chip shared memory
- Efficient use of parallelism to reduce power consumption
-
Dynamic Voltage and Frequency Scaling (DVFS) Research: While not mentioned in the provided search results, DVFS is a well-researched area for GPU power management. Many papers discuss implementing DVFS for CUDA applications to optimize power consumption dynamically.
-
Power-Aware GPU Scheduling: Research in this area focuses on scheduling GPU tasks with power constraints in mind. While not exactly like your tool, these approaches aim to manage power consumption at a higher level.
For your literature review, you could structure it as follows:
- Introduction to GPU power management in HPC environments
- Static power management techniques (e.g., nvidia-smi)
- Predictive approaches (e.g., the machine learning-based approach from [1])
- Dynamic power management techniques (DVFS research)
- Power-aware scheduling and workload management
- Gaps in current research and tools (where your tool would fit)
Your proposed tool, which changes power limits at runtime for CUDA applications, appears to fill a gap between static power management (like nvidia-smi) and predictive approaches. It could potentially combine real-time application performance metrics with dynamic power limit adjustments, which would be a novel contribution to the field.
To strengthen your research, consider exploring how your tool could integrate with or improve upon existing approaches, such as combining it with predictive models or enhancing it with application-specific optimizations based on the strategies discussed in optimization literature like [2].
Citations: [1] https://dl.acm.org/doi/10.1145/3603533 [2] https://www.enseignement.polytechnique.fr/profs/informatique/Eric.Goubault/Cours09/CUDA/SC07_CUDA_5_Optimization_Harris.pdf [3] https://gist.github.com/jctosta/b968a6edc592ad7d06d9c91bd0796024 [4] https://massedcompute.com/faq-answers/?question=How+do+I+monitor+and+control+power+consumption+of+NVIDIA+data+center+GPUs+using+CUDA+GPU+settings%3F [5] https://linuxconfig.org/how-to-set-nvidia-power-limit-on-ubuntu [6] https://www.sciencedirect.com/science/article/abs/pii/S0167739X23001267 [7] https://forums.developer.nvidia.com/t/limit-sm-speed/259615
Question: I have a single GPU. I want to install slurm on it so that i can submit a slurm job and emulate a slurm manager like a cluster on it. is it possible and if yes, give detailed instructions for my use case on how to set it up? Answer: Yes, it’s possible to set up Slurm on a single machine with a GPU to emulate a cluster environment. This setup is often called a “single-node cluster” and can be useful for testing and development purposes. Here’s a detailed guide on how to set this up:
Prerequisites
- Ubuntu 20.04 or later (instructions may need slight modifications for other distributions)
- Root or sudo access
- NVIDIA GPU with installed drivers
Installation Steps
-
Update your system:
sudo apt update && sudo apt upgrade -y -
Install Slurm and its dependencies:
sudo apt install slurm-wlm -y -
Create Slurm user and group:
sudo groupadd -g 64030 slurm sudo useradd -m -c "Slurm workload manager" -d /var/lib/slurm -u 64030 -g slurm -s /bin/bash slurm -
Create necessary directories:
sudo mkdir -p /var/spool/slurm /var/run/slurm-llnl /var/log/slurm sudo chown slurm:slurm /var/spool/slurm /var/run/slurm-llnl /var/log/slurm -
Configure Slurm: Create a new Slurm configuration file:
sudo nano /etc/slurm-llnl/slurm.confAdd the following content (adjust as needed):
ClusterName=localhost SlurmctldHost=localhost MpiDefault=none ProctrackType=proctrack/linuxproc ReturnToService=1 SlurmctldPidFile=/var/run/slurm-llnl/slurmctld.pid SlurmdPidFile=/var/run/slurm-llnl/slurmd.pid SlurmdSpoolDir=/var/spool/slurm SlurmUser=slurm StateSaveLocation=/var/spool/slurm SwitchType=switch/none TaskPlugin=task/affinity # SCHEDULING SchedulerType=sched/backfill SelectType=select/cons_tres SelectTypeParameters=CR_Core # LOGGING AND ACCOUNTING AccountingStorageType=accounting_storage/none JobAcctGatherType=jobacct_gather/none SlurmctldLogFile=/var/log/slurm/slurmctld.log SlurmdLogFile=/var/log/slurm/slurmd.log # COMPUTE NODES NodeName=localhost CPUs=1 RealMemory=1000 State=UNKNOWN PartitionName=debug Nodes=localhost Default=YES MaxTime=INFINITE State=UP # GPU Configuration GresTypes=gpu NodeName=localhost Gres=gpu:1 -
Configure GRES (Generic Resource Scheduling) for GPU: Create a new file:
sudo nano /etc/slurm-llnl/gres.confAdd the following content:
NodeName=localhost Name=gpu File=/dev/nvidia0 -
Start Slurm services:
sudo systemctl enable slurmd slurmctld sudo systemctl start slurmd slurmctld -
Verify Slurm is running:
sudo scontrol show node sinfo
Using Slurm with GPU
Now you can submit GPU jobs using Slurm. Here’s an example job script:
#!/bin/bash
#SBATCH --job-name=gpu_test
#SBATCH --output=gpu_test_%j.out
#SBATCH --error=gpu_test_%j.err
#SBATCH --ntasks=1
#SBATCH --gres=gpu:1
nvidia-smi
python your_gpu_script.pySubmit the job:
sbatch your_job_script.shTroubleshooting
- If you encounter issues, check the Slurm logs in
/var/log/slurm/. - Ensure your NVIDIA drivers are correctly installed and working.
- You may need to adjust the configuration based on your specific hardware and requirements.
This setup provides a basic Slurm environment on a single machine with GPU support. It’s suitable for testing and development but not recommended for production use. For a production environment, you’d typically use multiple nodes and more complex configurations.
Citations: [1] https://techcommunity.microsoft.com/t5/azure-high-performance-computing/creating-a-slurm-cluster-for-scheduling-nvidia-mig-based-gpu/ba-p/4183835 [2] https://docs.alliancecan.ca/wiki/Using_GPUs_with_Slurm [3] https://slurm.schedmd.com/gres.html [4] https://github.com/Lightning-AI/pytorch-lightning/issues/18950 [5] https://stackoverflow.com/questions/51763921/prevent-direct-use-of-gpu-in-single-node-slurm-setup [6] https://centml.ai/guide-gpu-clusters/ [7] https://research.aimultiple.com/gpu-cluster/ [8] https://github.com/Emanem/nv-pwr-ctrl
Question: i am using this change the steps accordingly: https://github.com/SergioMEV/slurm-for-dummies Answer: It appears that your Slurm controller (slurmctld) is not running or not accessible. Let’s troubleshoot this issue step by step:
-
First, check the status of the Slurm controller:
sudo systemctl status slurmctld -
If it’s not running, try to start it:
sudo systemctl start slurmctld -
Check the Slurm controller logs for any errors:
sudo less /var/log/slurm/slurmctld.log -
Make sure the Munge service is running:
sudo systemctl status mungeIf it’s not running, start it:
sudo systemctl start munge -
Verify that the Slurm configuration file is correct:
sudo slurmd -CThis command will show the node configuration as seen by slurmd. Make sure it matches your expectations.
-
Check if the Slurm user has the necessary permissions:
ls -l /var/spool/slurm ls -l /var/run/slurm-llnlThese directories should be owned by the Slurm user.
-
If you’ve made any changes to the Slurm configuration, restart both slurmd and slurmctld:
sudo systemctl restart slurmd slurmctld -
Check if the firewall is blocking Slurm ports:
sudo ufw statusIf it’s active, you might need to allow Slurm ports.
-
Verify that the hostname in your Slurm configuration matches your actual hostname:
hostnameMake sure this matches the NodeName in your slurm.conf file.
-
If none of the above steps work, try reconfiguring Slurm:
sudo slurmctld -c
After performing these steps, try running sinfo and srun hostname again. If you’re still encountering issues, please provide the output of the following commands:
sudo systemctl status slurmctld
sudo systemctl status slurmd
sudo systemctl status munge
cat /etc/slurm/slurm.conf | grep -v '^#' | grep -v '^$'
hostname
This information will help in further diagnosing the issue.
Question: Since the cuda application will contain multiple cuda kernels, When the slurm job runs it will run run the compiled executable file of the cuda application, and not the .cu script itself. Now I want to extract the cuda kernel metrics to change power level in realtime during execution, how can i do that? Answer: Based on your requirements and the context provided, here’s an approach to extract CUDA kernel metrics and change power levels in real-time during execution of a Slurm job:
-
Instrument your CUDA application: Use NVIDIA’s CUPTI (CUDA Profiling Tools Interface) to instrument your application. This allows you to collect metrics without modifying your original CUDA code.
-
Create a monitoring process: Develop a separate process that runs alongside your CUDA application to monitor metrics and adjust power levels.
-
Inter-process communication: Use shared memory or another IPC mechanism to communicate between your CUDA application and the monitoring process.
-
Power adjustment: Use NVIDIA Management Library (NVML) in your monitoring process to adjust GPU power limits.
Here’s a more detailed breakdown:
1. Instrument your CUDA application
Use CUPTI to instrument your application. In your CUDA application’s main file:
#include <cupti.h>
// CUPTI callback function
void CUPTIAPI callback_func(void *userdata, CUpti_CallbackDomain domain,
CUpti_CallbackId cbid, const void *cbdata) {
// Extract kernel metrics here
// Write metrics to shared memory
}
int main(int argc, char **argv) {
// Initialize CUPTI
cuptiSubscribe(&subscriber, (CUpti_CallbackFunc)callback_func, NULL);
cuptiEnableDomain(1, subscriber, CUPTI_CB_DOMAIN_RUNTIME_API);
// Rest of your CUDA application code
// ...
// Cleanup CUPTI
cuptiUnsubscribe(subscriber);
return 0;
}2. Create a monitoring process
Create a separate C/C++ program that runs alongside your CUDA application:
#include <nvml.h>
#include <sys/shm.h>
int main() {
// Initialize NVML
nvmlInit();
// Attach to shared memory
int shmid = shmget(SHM_KEY, SHM_SIZE, 0666);
void *shm = shmat(shmid, NULL, 0);
while (1) {
// Read metrics from shared memory
// Analyze metrics
// Adjust power if necessary using NVML
nvmlDeviceSetPowerManagementLimit(device, new_power_limit);
sleep(1); // Wait before next check
}
// Cleanup
shmdt(shm);
nvmlShutdown();
return 0;
}3. Modify your Slurm job script
Update your Slurm script to run both the CUDA application and the monitoring process:
#!/bin/bash
#SBATCH --job-name=cuda_power_managed
#SBATCH --output=output_%j.log
#SBATCH --error=error_%j.log
#SBATCH --ntasks=1
#SBATCH --gres=gpu:1
# Start the monitoring process in the background
./monitor &
# Run the CUDA application
./cuda_application
# Wait for both processes to finish
wait4. Compile and run
Compile your CUDA application with CUPTI support:
nvcc -o cuda_application main.cu -lcuptiCompile the monitoring process:
gcc -o monitor monitor.c -lnvmlSubmit the Slurm job:
sbatch job_script.shThis approach allows you to:
- Extract kernel metrics in real-time using CUPTI
- Communicate these metrics to a separate process via shared memory
- Analyze the metrics and adjust GPU power limits using NVML
- Do all of this within a Slurm job running your compiled CUDA executable
Remember to handle error cases, implement proper synchronization between processes, and thoroughly test your solution. Also, ensure that your Slurm environment allows for NVML operations and that you have the necessary permissions to change GPU power limits.
Citations: [1] https://developer.nvidia.com/nsight-compute-1_0 [2] https://docs.nvidia.com/cuda/profiler-users-guide/index.html [3] https://developer.nvidia.com/blog/how-implement-performance-metrics-cuda-cc/ [4] https://cuda.juliagpu.org/stable/development/profiling/ [5] https://developer.nvidia.com/cupti [6] https://techcommunity.microsoft.com/t5/azure-high-performance-computing/creating-a-slurm-cluster-for-scheduling-nvidia-mig-based-gpu/ba-p/4183835 [7] https://developer.nvidia.com/slurm [8] https://slurm.schedmd.com/gres.html [9] https://docs.nvidia.com/nsight-compute/ProfilingGuide/index.html
Question: Extract all the metric available for this matrixmul cuda kernel, give the instrumented code with cupti, that output the recorded metric: Answer: Based on the provided CUDA matrix multiplication kernel and the CUPTI documentation, I can help you instrument the code to extract metrics. Here’s an approach to instrument the code and extract metrics using CUPTI:
-
First, let’s identify some relevant metrics for the matrix multiplication kernel:
- SM efficiency
- Achieved occupancy
- Global memory load/store throughput
- Shared memory load/store throughput
- Flop efficiency
-
Here’s an instrumented version of the main function that uses CUPTI to collect these metrics:
#include <cupti.h>
#include <nvperf_host.h>
#include <nvperf_cuda_host.h>
// ... (other includes and kernel definition remain the same)
#define METRIC_COUNT 5
int main(int argc, char **argv) {
// ... (existing setup code)
// Initialize CUPTI and NVPW
CUpti_Profiler_Initialize_Params profilerInitializeParams = {CUpti_Profiler_Initialize_Params_STRUCT_SIZE};
CUPTI_CALL(cuptiProfilerInitialize(&profilerInitializeParams));
// Create CUPTI subscriber
CUpti_SubscriberHandle subscriber;
CUPTI_CALL(cuptiSubscribe(&subscriber, (CUpti_CallbackFunc)callbackHandler, NULL));
CUPTI_CALL(cuptiEnableDomain(1, subscriber, CUPTI_CB_DOMAIN_RUNTIME_API));
// Set up metrics
const char* metricNames[] = {
"sm__efficiency.avg.pct",
"sm__occupancy.avg.pct_of_theoretical_active_warps",
"dram__throughput.avg.pct_of_peak_sustained_elapsed",
"smsp__sass_thread_inst_executed_op_memory_shared.sum.pct_of_peak_sustained_elapsed",
"smsp__sass_thread_inst_executed_ops_dadd_dmul_dfma.avg.pct_of_peak_sustained_elapsed"
};
// Configure metrics
CUpti_Profiler_BeginSession_Params beginSessionParams = {CUpti_Profiler_BeginSession_Params_STRUCT_SIZE};
beginSessionParams.ctx = 0;
beginSessionParams.counterDataImageSize = 0;
beginSessionParams.pCounterDataImage = NULL;
beginSessionParams.counterDataScratchBufferSize = 0;
beginSessionParams.pCounterDataScratchBuffer = NULL;
beginSessionParams.range = CUPTI_AutoRange;
beginSessionParams.replayMode = CUPTI_KernelReplay;
beginSessionParams.maxRangesPerPass = 1;
beginSessionParams.maxLaunchesPerPass = 1;
CUPTI_CALL(cuptiProfilerBeginSession(&beginSessionParams));
// Set up metric groups
CUpti_Profiler_SetConfig_Params setConfigParams = {CUpti_Profiler_SetConfig_Params_STRUCT_SIZE};
setConfigParams.pConfig = NULL;
setConfigParams.configSize = 0;
setConfigParams.passIndex = 0;
CUPTI_CALL(cuptiProfilerSetConfig(&setConfigParams));
// ... (existing kernel launch code)
// Collect profiling data
CUpti_Profiler_EndPass_Params endPassParams = {CUpti_Profiler_EndPass_Params_STRUCT_SIZE};
CUPTI_CALL(cuptiProfilerEndPass(&endPassParams));
CUpti_Profiler_FlushCounterData_Params flushCounterDataParams = {CUpti_Profiler_FlushCounterData_Params_STRUCT_SIZE};
CUPTI_CALL(cuptiProfilerFlushCounterData(&flushCounterDataParams));
// Get metric values
CUpti_Profiler_Evaluate_Params evaluateParams = {CUpti_Profiler_Evaluate_Params_STRUCT_SIZE};
evaluateParams.pMetricNames = metricNames;
evaluateParams.metricNameCount = METRIC_COUNT;
CUPTI_CALL(cuptiProfilerEvaluate(&evaluateParams));
// Print metric values
for (int i = 0; i < METRIC_COUNT; i++) {
printf("%s: %f\n", metricNames[i], evaluateParams.pMetricValues[i]);
}
// Clean up CUPTI resources
CUpti_Profiler_UnsetConfig_Params unsetConfigParams = {CUpti_Profiler_UnsetConfig_Params_STRUCT_SIZE};
CUPTI_CALL(cuptiProfilerUnsetConfig(&unsetConfigParams));
CUpti_Profiler_EndSession_Params endSessionParams = {CUpti_Profiler_EndSession_Params_STRUCT_SIZE};
CUPTI_CALL(cuptiProfilerEndSession(&endSessionParams));
CUPTI_CALL(cuptiProfilerDeInitialize(&profilerInitializeParams));
// ... (existing cleanup code)
return 0;
}This instrumented code will:
- Initialize CUPTI profiler
- Set up the metrics we want to collect
- Configure the profiling session
- Run the matrix multiplication kernel
- Collect and evaluate the metrics
- Print the metric values
- Clean up CUPTI resources
Note that you’ll need to include the appropriate CUPTI headers and link against the CUPTI library when compiling this code. Also, error handling has been omitted for brevity, but you should add proper error checking in a production environment.
This instrumentation will give you valuable insights into the performance characteristics of your matrix multiplication kernel, including SM efficiency, occupancy, memory throughput, and floating-point operation efficiency.
Citations: [1] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/1401754/314a1fb3-0031-4bdf-a270-f1a835c8a858/paste.txt [2] https://docs.nvidia.com/cupti/overview/overview.html [3] https://dl.acm.org/doi/fullHtml/10.1145/3295690 [4] https://developer.nvidia.com/cupti-1_0 [5] https://developer.nvidia.com/blog/how-implement-performance-metrics-cuda-cc/ [6] https://stackoverflow.com/questions/9714140/cupti-blocks-cuda-kernel-launch-in-multi-threaded-code [7] https://forums.developer.nvidia.com/t/can-we-use-cupti-for-run-time-analysis-of-cuda-applications-for-gpu-metrics/269147 [8] https://stackoverflow.com/questions/74693922/how-to-use-cupti-to-get-metrics-related-to-launch-metrics-source-metrics-and-in
Question: Create a plan for CFG.. Answer: To create an energy optimizer that parses a CUDA binary executable without execution and preemptively adjusts GPU power limits, you’ll need to combine several techniques. Here’s an approach to achieve this:
-
Parse the CUDA binary: Use tools like cuobjdump or nvdisasm to extract the SASS (Shader Assembly) code and control flow graph (CFG) from the CUDA binary.
-
Analyze the CFG: Develop a custom parser to process the CFG and extract relevant information such as:
- Instruction types (arithmetic, memory access, control flow)
- Estimated FLOPs per basic block
- Estimated memory accesses per basic block
-
Static analysis: Perform static analysis on the parsed CFG to estimate:
- Computational intensity
- Memory access patterns
- Potential parallelism
-
Create a power model: Develop a model that correlates instruction types and their frequencies with power consumption. This may require initial profiling of representative kernels to establish baseline correlations.
-
Segment the application: Divide the application into stages based on the CFG analysis, identifying regions with different computational characteristics.
-
Develop a power management strategy: Create rules for adjusting power limits based on the characteristics of each segment.
-
Runtime power adjustment: Implement a runtime component that applies the power management strategy as the application executes.
Here’s a more detailed breakdown of these steps:
import networkx as nx
from pynvml import *
def parse_cuda_binary(binary_path):
# Use cuobjdump or nvdisasm to extract SASS and CFG
# Return parsed CFG
def analyze_cfg(cfg):
# Analyze the CFG to extract instruction types, FLOPs, memory accesses
# Return analysis results
def estimate_power_consumption(analysis_results):
# Use a power model to estimate power consumption for each segment
# Return power estimates
def create_power_management_strategy(power_estimates):
# Create rules for adjusting power limits
# Return power management strategy
def apply_power_limits(strategy):
nvmlInit()
device = nvmlDeviceGetHandleByIndex(0)
for segment, power_limit in strategy:
# Wait for the appropriate point in execution (you may need to implement triggers)
nvmlDeviceSetPowerManagementLimit(device, power_limit)
nvmlShutdown()
# Main execution
binary_path = "path_to_cuda_binary"
cfg = parse_cuda_binary(binary_path)
analysis_results = analyze_cfg(cfg)
power_estimates = estimate_power_consumption(analysis_results)
power_strategy = create_power_management_strategy(power_estimates)
# This would be called when the CUDA application is launched
apply_power_limits(power_strategy)To correlate the CFG with energy consumption and obtain metrics like FLOPs and memory usage:
-
Use NVIDIA’s CUPTI (CUDA Profiling Tools Interface) to instrument the code and collect runtime metrics.
-
For each basic block in the CFG, you can collect:
- FLOPs: Use CUPTI metrics like
flop_count_spfor single-precision operations. - Memory usage: Use metrics like
dram_read_transactionsanddram_write_transactions. - Power consumption: Use NVML to sample power during execution.
- FLOPs: Use CUPTI metrics like
-
Map these runtime metrics back to the CFG by correlating timestamps or using CUPTI’s correlation capabilities.
Here’s a basic example of how you might use CUPTI to collect some of these metrics:
#include <cupti.h>
#define CUPTI_CALL(call) \
do { \
CUptiResult _status = call; \
if (_status != CUPTI_SUCCESS) { \
const char *errstr; \
cuptiGetResultString(_status, &errstr); \
fprintf(stderr, "%s:%d: error: function %s failed with error %s.\n", \
__FILE__, __LINE__, #call, errstr); \
exit(-1); \
} \
} while (0)
void CUPTIAPI getValueCallback(void *userdata, CUpti_CallbackDomain domain,
CUpti_CallbackId cbid, const void *cbInfo)
{
const CUpti_CallbackData *cbData = (CUpti_CallbackData *)cbInfo;
if (cbData->callbackSite == CUPTI_API_ENTER) {
// Collect metrics at kernel launch
// You would implement logic here to map to your CFG
}
}
int main(int argc, char *argv[])
{
CUpti_SubscriberHandle subscriber;
CUPTI_CALL(cuptiSubscribe(&subscriber, (CUpti_CallbackFunc)getValueCallback, NULL));
CUPTI_CALL(cuptiEnableDomain(1, subscriber, CUPTI_CB_DOMAIN_RUNTIME_API));
// Run your CUDA application here
CUPTI_CALL(cuptiUnsubscribe(subscriber));
return 0;
}This approach provides a framework for creating an energy optimizer that can analyze CUDA binaries, estimate power requirements, and dynamically adjust GPU power limits during execution. Remember that this is a complex task that requires careful implementation and testing, especially to ensure that power limit changes don’t negatively impact application performance.
Citations: [1] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/1401754/314a1fb3-0031-4bdf-a270-f1a835c8a858/paste.txt [2] https://forums.developer.nvidia.com/t/how-to-measure-tensor-flops/292765 [3] https://docs.nvidia.com/cuda/profiler-users-guide/index.html [4] https://docs.nvidia.com/gameworks/content/developertools/desktop/analysis/report/cudaexperiments/kernellevel/achievedoccupancy.htm [5] https://ieeexplore.ieee.org/document/9235065 [6] https://massedcompute.com/faq-answers/?question=What+are+the+different+NVML+functions+for+monitoring+GPU+power+consumption%3F [7] https://github.com/NVIDIA/open-gpu-kernel-modules/issues/483 [8] https://blogs.nvidia.com/blog/cuda-accelerated-computing-energy-efficiency/ [9] https://forums.developer.nvidia.com/t/online-power-optimization-with-feedback-of-the-performance/299813
Question: i want to train a model that predicts power limit for blocks of cfg generated from cuda cubin binary, and when the binary executes i want to change the power limit to the predicted value of power limit in sync with the control flow graph. how can i do it
Answer: To train a model that predicts power limits for blocks of a Control Flow Graph (CFG) generated from a CUDA cubin binary and dynamically adjust power limits during execution, you’ll need to follow these steps:
- Extract CFG from CUDA binary
- Generate features for each CFG block
- Collect power consumption data
- Train a prediction model
- Implement runtime power limit adjustment
Here’s a detailed approach:
-
Extract CFG from CUDA binary: Use cuobjdump to extract the CFG:
cuobjdump -cfg your_cuda_binary > cfg_output.txtParse the output to create a graph structure (e.g., using NetworkX).
-
Generate features for each CFG block: Analyze each block to extract relevant features, such as:
- Instruction count
- Arithmetic intensity
- Memory access patterns
- Branch complexity
-
Collect power consumption data: Profile the application using NVIDIA’s CUPTI and NVML to collect power consumption data for each block.
import pycuda.driver as cuda import pycuda.autoinit from pynvml import * nvmlInit() device = nvmlDeviceGetHandleByIndex(0) def collect_power_data(kernel_function): start = cuda.Event() end = cuda.Event() start.record() kernel_function() end.record() end.synchronize() power = nvmlDeviceGetPowerUsage(device) return power # Collect power data for each block -
Train a prediction model: Use the collected data to train a machine learning model (e.g., Random Forest or Neural Network) that predicts power consumption based on block features.
from sklearn.ensemble import RandomForestRegressor from sklearn.model_selection import train_test_split X = block_features y = power_consumption_data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) model = RandomForestRegressor() model.fit(X_train, y_train) -
Implement runtime power limit adjustment: Create a runtime component that tracks the current block being executed and adjusts the power limit based on the model’s prediction.
import pynvml pynvml.nvmlInit() handle = pynvml.nvmlDeviceGetHandleByIndex(0) def adjust_power_limit(block_id): features = get_block_features(block_id) predicted_power = model.predict([features])[0] pynvml.nvmlDeviceSetPowerManagementLimit(handle, int(predicted_power)) # In your CUDA application def kernel_wrapper(): for block in cfg_blocks: adjust_power_limit(block.id) execute_block(block)
To synchronize power limit changes with the CFG execution:
-
Instrument your CUDA code to signal block transitions:
extern "C" void __cudaRegisterFunction(...); extern "C" void signal_block_transition(int block_id); __global__ void my_kernel(...) { // Your existing kernel code signal_block_transition(1); // More code signal_block_transition(2); // ... } // In host code cudaRegisterFunction(..., (void*)signal_block_transition, ...); -
Implement the signal_block_transition function to adjust power limits:
void signal_block_transition(int block_id) { adjust_power_limit(block_id); } -
Use CUDA’s Dynamic Parallelism or Cooperative Groups to ensure synchronization between thread blocks if necessary.
Remember that frequently changing power limits may introduce overhead, so you might want to adjust limits only for significant changes or at certain intervals.
This approach provides a framework for predicting and dynamically adjusting power limits based on the CFG of a CUDA binary. It requires careful implementation and testing to ensure that the power limit changes don’t negatively impact performance. You may need to fine-tune the prediction model and adjustment strategy based on your specific application characteristics.
Citations: [1] paste.txt https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/1401754/314a1fb3-0031-4bdf-a270-f1a835c8a858/paste.txt [2] CUDA Binary Utilities - NVIDIA Docs https://docs.nvidia.com/cuda/cuda-binary-utilities/index.html [3] how to extract ptx from cuda exe and some related cuda compiler … https://stackoverflow.com/questions/6418741/how-to-extract-ptx-from-cuda-exe-and-some-related-cuda-compiler-questions [4] [PDF] cuda-binary-utilities | NVIDIA Docs https://docs.nvidia.com/cuda/pdf/CUDA_Binary_Utilities.pdf [5] Accelerating NetworkX on NVIDIA GPUs for High Performance Graph Analytics | NVIDIA Technical Blog https://developer.nvidia.com/blog/accelerating-networkx-on-nvidia-gpus-for-high-performance-graph-analytics/ [6] Program Analysis and Machine Learning–based Approach to Predict Power Consumption of CUDA Kernel https://dl.acm.org/doi/10.1145/3603533 [7] Predicting the Energy consumption of CUDA kernels using SimGrid https://hal.science/hal-02924028/document [8] NVIDIA Management Library (NVML) https://developer.nvidia.com/management-library-nvml [9] How to Implement Performance Metrics in CUDA C/C++ | NVIDIA Technical Blog https://developer.nvidia.com/blog/how-implement-performance-metrics-cuda-cc/
Question: current works do this: Existing Novelties: Static analysis-based power prediction without executing the CUDA kernel Comprehensive feature engineering process combining domain knowledge and data-driven approaches Comparison of multiple advanced machine learning techniques for power prediction Analysis across multiple GPU architectures (Kepler, Maxwell, Volta) Use of parallel dwarfs to analyze model performance across different types of applications. what novelties can i add to my work to improve quality in different aspects like, novelty, implication, usage, performance, etc Answer: Based on the current state of the art and the existing novelties you’ve mentioned, here are some innovative ideas to enhance your work on GPU power prediction:
-
Dynamic Power Prediction and Adaptation: Develop a model that can predict power consumption in real-time as the kernel executes, allowing for dynamic power management. This could involve:
- Creating a lightweight runtime system that monitors key metrics during execution
- Implementing an online learning algorithm that adapts predictions based on real-time data
- Developing a feedback loop that adjusts GPU power states based on predictions
-
Multi-Kernel Workload Optimization: Extend your model to optimize power consumption across multiple kernels in a complex application:
- Develop a scheduler that uses power predictions to optimize kernel execution order
- Implement inter-kernel power management strategies
-
Transfer Learning for New GPU Architectures: Create a model that can quickly adapt to new GPU architectures with minimal retraining:
- Implement transfer learning techniques to leverage knowledge from existing architectures
- Develop a method to automatically identify and adapt to architectural differences
-
Fine-grained Instruction-Level Power Modeling: Enhance your static analysis to provide instruction-level power predictions:
- Create a detailed model of power consumption for individual SASS instructions
- Develop techniques to aggregate instruction-level predictions into block and kernel-level estimates
-
Integration with Compiler Optimizations: Develop a framework that uses your power prediction model to guide compiler optimizations:
- Create power-aware optimization passes in a CUDA compiler
- Implement automatic code transformations to reduce predicted power consumption
-
Thermal-Aware Power Modeling: Incorporate thermal modeling into your power prediction:
- Develop a coupled power-thermal model that considers the impact of temperature on power consumption
- Create strategies for thermal-aware kernel scheduling and power management
-
Memory-Centric Power Modeling: Develop specialized models for memory-intensive operations:
- Create detailed models of power consumption for different memory access patterns
- Implement techniques to optimize memory operations for power efficiency
-
Power Prediction for Emerging GPU Workloads: Extend your model to handle new types of GPU computations:
- Develop power models for ray tracing operations
- Create specialized predictions for AI and machine learning workloads
-
Explainable AI for Power Prediction: Implement techniques to provide insights into power consumption patterns:
- Use interpretable machine learning models to explain predictions
- Develop visualizations that highlight power-hungry code sections
-
Cross-Platform Power Modeling: Create a unified model for predicting power across different accelerators:
- Develop a common framework for modeling GPUs, FPGAs, and other accelerators
- Implement techniques for power-efficient workload distribution in heterogeneous systems
-
Integration with High-Level Programming Models: Extend your work to provide power predictions for high-level GPU programming models:
- Develop power prediction techniques for OpenACC or SYCL code
- Create tools that provide power consumption estimates during development
These novel approaches could significantly enhance the impact and applicability of your research. They address current gaps in GPU power modeling and optimization, opening up new avenues for practical applications in areas like green computing, mobile GPU optimization, and high-performance computing.
Citations: [1] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/1401754/314a1fb3-0031-4bdf-a270-f1a835c8a858/paste.txt [2] https://epochai.org/blog/predicting-gpu-performance [3] https://dl.acm.org/doi/fullHtml/10.1145/3431731 [4] https://dl.acm.org/doi/10.1145/3603533 [5] https://dl.acm.org/doi/10.1145/2856636.2856643 [6] https://dl.acm.org/doi/fullHtml/10.1145/3522712 [7] https://arxiv.org/abs/2305.01886 [8] https://dl.acm.org/doi/fullHtml/10.1145/3466752.3480063
Question: I have a binary cuda file. I want to create an optimizer that is novel from past research. Create a detailed plan, including feature engineering in training as well as inference Answer: Based on your request and the context of previous work in GPU power prediction, here’s a detailed plan for creating a novel optimizer using a binary CUDA file:
-
Binary Analysis and Feature Extraction:
- Use tools like cuobjdump or nvdisasm to extract SASS code from the binary.
- Develop a custom parser to analyze the SASS instructions and extract relevant features: a) Instruction mix (percentage of arithmetic, memory, control flow instructions) b) Register usage patterns c) Memory access patterns (global, shared, texture memory usage) d) Thread and block configurations e) Instruction-level parallelism potential
- Create a graph representation of the control flow to capture kernel structure.
-
Advanced Feature Engineering:
- Develop a “power profile signature” for each kernel based on its instruction mix and memory access patterns.
- Create “temporal features” that capture how instruction patterns change over the course of kernel execution.
- Generate “cross-kernel features” that represent relationships between different kernels in the application.
- Implement “architectural sensitivity features” that estimate how the kernel might perform on different GPU architectures.
-
Machine Learning Model Development:
- Create an ensemble model combining: a) A graph neural network (GNN) to process the control flow graph b) A recurrent neural network (RNN) to handle temporal features c) A traditional ML model (e.g., XGBoost) for other engineered features
- Implement transfer learning techniques to adapt the model across different GPU architectures.
-
Dynamic Power Prediction System:
- Develop a lightweight runtime system that can: a) Track kernel execution progress b) Collect real-time performance counters c) Update power predictions on-the-fly
- Implement an online learning component to fine-tune predictions based on actual power measurements.
-
Adaptive Power Management:
- Create a power state transition model that optimizes for both performance and energy efficiency.
- Implement a predictive DVFS (Dynamic Voltage and Frequency Scaling) algorithm that anticipates future power needs.
- Develop a “power budget allocation” system for multi-kernel workloads.
-
Thermal-Aware Optimization:
- Integrate a thermal model that predicts GPU temperature based on power consumption and workload characteristics.
- Implement a joint power-thermal optimization strategy.
-
Memory-Centric Power Optimization:
- Develop specialized prediction and optimization strategies for memory-bound kernels.
- Implement adaptive memory throttling techniques based on predicted power consumption.
-
Multi-Objective Optimization:
- Create a system that balances power efficiency, performance, and thermal constraints.
- Implement a Pareto optimization approach to find optimal trade-offs.
-
Explainable AI Integration:
- Develop visualizations that highlight power-hungry code sections in the original CUDA source.
- Implement a recommendation system for power-efficient code transformations.
-
Continuous Learning and Adaptation:
- Create a feedback loop that continuously improves the model based on observed power consumption across multiple runs and applications.
- Implement an “experience database” that stores power profiles for different types of kernels and GPU architectures.
Training Phase:
- Collect a diverse dataset of CUDA binaries and their corresponding power consumption on various GPU architectures.
- Use the feature extraction and engineering techniques described above.
- Train the ensemble model using cross-validation and hyperparameter optimization.
Inference Phase:
- Extract features from the new CUDA binary.
- Use the trained model to predict power consumption and generate an optimized power management strategy.
- Implement the dynamic power prediction system to adjust predictions in real-time.
- Apply the adaptive power management techniques based on predictions and runtime feedback.
This approach combines static analysis, machine learning, and dynamic adaptation to create a novel, comprehensive power optimization system for CUDA applications. It addresses several gaps in existing research and provides a flexible framework that can adapt to different applications and GPU architectures.
Citations: [1] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/1401754/314a1fb3-0031-4bdf-a270-f1a835c8a858/paste.txt [2] https://community.intel.com/t5/Intel-Graphics-Performance/How-to-get-GPU-power-in-Watt/m-p/1610960 [3] https://docs.nvidia.com/cuda/profiler-users-guide/index.html [4] https://dl.acm.org/doi/fullHtml/10.1145/3431731 [5] https://scholarworks.calstate.edu/downloads/z603r3384 [6] https://people.ece.ubc.ca/~aamodt/publications/papers/gpuwattch.isca2013.pdf [7] https://docs.nvidia.com/cuda/cuda-binary-utilities/index.html [8] https://www.clear.rice.edu/comp422/resources/cuda/pdf/CUDA_Binary_Utilities.pdf [9] https://dl.acm.org/doi/fullHtml/10.1145/3466752.3480063
Question: Create a detailed plan Answer: Based on our previous discussion, here’s a detailed plan to create a novel optimizer using a binary CUDA file:
-
Advanced Static Analysis:
- Develop a custom CUDA binary parser to extract low-level features: • Instruction counts by type (compute, memory, control) • Register usage • Shared memory allocation • Thread and block configurations
- Implement control flow graph (CFG) construction from the binary
- Create a data flow analysis module to estimate memory access patterns
-
Feature Engineering:
- Develop composite features: • Instruction mix ratios • Estimated arithmetic intensity • Control flow complexity metrics
- Create architecture-specific features based on known GPU specifications
- Implement a feature selection pipeline using correlation analysis and importance ranking
-
Machine Learning Model:
- Develop an ensemble model combining: • Graph Neural Network (GNN) for CFG analysis • Gradient Boosting (XGBoost/CatBoost) for numerical features
- Implement transfer learning to adapt across GPU architectures
- Use multi-task learning to predict both power and performance
-
Dynamic Adaptation:
- Create a lightweight runtime monitoring system
- Implement online learning to fine-tune predictions during execution
- Develop an adaptive power management strategy based on predictions
-
Optimization Strategy:
- Implement a multi-objective optimizer considering power, performance, and thermal constraints
- Develop a predictive DVFS algorithm
- Create a kernel scheduling system for multi-kernel workloads
-
Explainable AI Component:
- Develop a system to map power predictions back to source code
- Create visualizations of power hotspots in the code
- Implement a recommendation system for power-efficient code transformations
-
Continuous Improvement:
- Create a feedback loop to update the model based on actual measurements
- Develop an “experience database” of kernel power profiles
Training Phase:
- Collect a diverse dataset of CUDA binaries and power measurements
- Extract features using the developed static analysis tools
- Train the ensemble model using nested cross-validation
Inference Phase:
- Extract features from the new binary
- Use the trained model to predict power consumption
- Apply the optimization strategy based on predictions
- Implement runtime adaptation and continuous learning
This plan combines advanced static analysis, sophisticated machine learning techniques, and dynamic adaptation to create a novel, comprehensive power optimization system for CUDA applications. It addresses limitations in existing research and provides a flexible framework that can evolve with different applications and GPU architectures.
Question: Plan when using SASS instructions? Answer: To achieve each of the steps you’ve outlined using SASS instructions from a binary executable, you can follow these approaches:
- Advanced Static Analysis:
a) Develop a custom CUDA binary parser:
- Create a parser that reads the SASS instructions and extracts: • Instruction counts: Iterate through the instructions, categorizing each (e.g., MOV, S2R, ULDC as compute; LDG, STG as memory; BRA as control). • Register usage: Track R1, R2, R3, etc. in the “Live Registers” column. • Shared memory allocation: Look for instructions that reference shared memory. • Thread and block configurations: Parse instructions like S2R R2, SR_CTAID.X and S2R R3, SR_TID.X to infer configurations.
b) Implement CFG construction:
- Identify basic blocks (sequences of instructions without branches).
- Use branch instructions (e.g., BRA, not shown in the snippet) to connect basic blocks.
c) Data flow analysis:
- Track register dependencies across instructions.
- Analyze memory access instructions to estimate patterns.
- Feature Engineering:
a) Develop composite features:
- Instruction mix ratios: Calculate percentages of each instruction type.
- Estimated arithmetic intensity: Ratio of compute to memory instructions.
- Control flow complexity: Count branch instructions and basic blocks.
b) Architecture-specific features:
- Use known GPU specifications to interpret instructions (e.g., ULDC.64 for 64-bit operations).
c) Feature selection:
- Implement correlation analysis between extracted features.
- Use techniques like Random Forest feature importance on your training data.
- Machine Learning Model:
a) Develop an ensemble model:
- GNN for CFG: Convert the CFG into a graph representation suitable for GNN input.
- XGBoost/CatBoost: Use numerical features extracted from SASS analysis.
b) Transfer learning:
- Train on data from multiple GPU architectures.
- Fine-tune the model for specific architectures.
c) Multi-task learning:
- Define a loss function that combines power and performance prediction errors.
- Dynamic Adaptation:
While static analysis of SASS doesn’t directly enable dynamic adaptation, you can prepare for it:
a) Lightweight runtime monitoring:
- Identify key instructions that could serve as checkpoints for runtime monitoring.
b) Online learning preparation:
- Design your model to accept runtime feedback and update predictions.
c) Adaptive power management:
- Based on static analysis, identify potential power states and transition points in the code.
To implement these steps, you’ll need to develop a comprehensive SASS instruction parser and analyzer. This will involve creating mappings between SASS instructions and their meanings, understanding GPU architecture details, and implementing sophisticated static analysis techniques. The machine learning components will then use the features extracted from this analysis to build the predictive models.
Question? Pros and cons of SASS vs PTZ, suggest changes? To analyze the pros and cons of using SASS (Shader Assembly) versus PTX (Parallel Thread Execution) for creating a just-in-time energy optimizer, let’s consider several factors:
Pros of using SASS:
-
Low-level optimization: SASS provides direct access to hardware-specific instructions, allowing for fine-grained optimizations.
-
Accurate power modeling: SASS instructions closely represent actual GPU operations, potentially leading to more accurate power consumption estimates.
-
Architecture-specific tuning: SASS allows for optimizations tailored to specific GPU architectures.
-
Runtime performance: SASS code is already in a form executable by the GPU, potentially reducing runtime overhead.
Cons of using SASS:
-
Portability: SASS is specific to particular GPU architectures, making it less portable across different NVIDIA GPU generations.
-
Complexity: SASS is more complex to analyze and manipulate than higher-level representations.
-
Maintenance: As GPU architectures evolve, SASS-based tools may require more frequent updates.
-
Limited availability: SASS code is not always readily available, especially for third-party libraries.
Pros of using PTX:
-
Portability: PTX is more portable across different NVIDIA GPU architectures.
-
Readability: PTX is more human-readable than SASS, making it easier to analyze and modify.
-
Stability: PTX provides a more stable intermediate representation across GPU generations.
-
Availability: PTX code is more commonly available and can be generated from CUDA source code.
Cons of using PTX:
-
Less precise hardware mapping: PTX is an intermediate representation, so it may not map directly to hardware-specific operations.
-
Potential performance overhead: Just-in-time compilation from PTX to SASS may introduce some runtime overhead.
-
Less accurate power modeling: The abstraction level of PTX may lead to less accurate power consumption estimates compared to SASS.
-
Limited access to hardware-specific features: Some low-level optimizations possible in SASS may not be accessible in PTX.
For a just-in-time energy optimizer:
Using SASS could provide more accurate power estimates and finer-grained control over optimizations, but at the cost of increased complexity and reduced portability.
Using PTX would offer better portability and ease of analysis, but might sacrifice some accuracy in power estimation and limit access to hardware-specific optimizations.
The choice between SASS and PTX would depend on factors such as the required level of accuracy, the range of GPU architectures to be supported, and the available development resources. A hybrid approach, using PTX for initial analysis and SASS for final optimization on specific architectures, could potentially combine the advantages of both.
Answer:
SASS instructions from the binary executable for creating a just-in-time energy optimizer:
- Advanced Static Analysis:
a) Develop a custom CUDA binary parser:
- Create a SASS instruction parser that categorizes instructions: • Compute: MOV, S2R, ULDC • Memory: Look for LDG, STG (not in the snippet) • Control: Look for branch instructions like BRA (not in the snippet)
- Track register usage: R1, R2, R3, R5, UR4
- Identify shared memory operations (not present in the snippet)
- Analyze thread and block configurations from instructions like: S2R R2, SR_CTAID.X S2R R3, SR_TID.X
b) CFG construction:
- Identify basic blocks in the SASS code
- Use branch instructions to connect these blocks
c) Data flow analysis:
- Track register dependencies (e.g., R1 → R2 → R5)
- Analyze memory access patterns in load/store instructions
- Feature Engineering:
a) Develop composite features:
- Calculate instruction mix ratios from SASS instruction counts
- Estimate arithmetic intensity based on compute vs. memory instructions
- Determine control flow complexity from branch instructions and basic blocks
b) Architecture-specific features:
- Interpret SASS instructions based on the target GPU architecture (e.g., ULDC.64 for 64-bit operations)
c) Feature selection:
- Implement correlation analysis on extracted SASS-based features
- Use techniques like Random Forest for feature importance ranking
- Machine Learning Model:
a) Develop an ensemble model:
- Convert the SASS-based CFG into a graph representation for GNN input
- Use numerical features from SASS analysis for XGBoost/CatBoost
b) Transfer learning:
- Train on SASS data from multiple GPU architectures
- Fine-tune for specific architectures based on their SASS instruction set
c) Multi-task learning:
- Predict both power and performance based on SASS instruction analysis
- Dynamic Adaptation:
While static SASS analysis doesn’t directly enable runtime adaptation, you can prepare for it:
a) Lightweight runtime monitoring:
- Identify key SASS instructions as potential runtime checkpoints
b) Online learning preparation:
- Design the model to incorporate runtime feedback for updating predictions
c) Adaptive power management:
- Use SASS analysis to identify potential power states and code transition points
By focusing on SASS instructions, we can potentially achieve more accurate power estimates and finer-grained optimizations. However, be aware of the increased complexity and reduced portability compared to using PTX. Consider implementing architecture-specific optimizations to fully leverage the low-level access provided by SASS.
Q: Features used in past literature:
Answer: 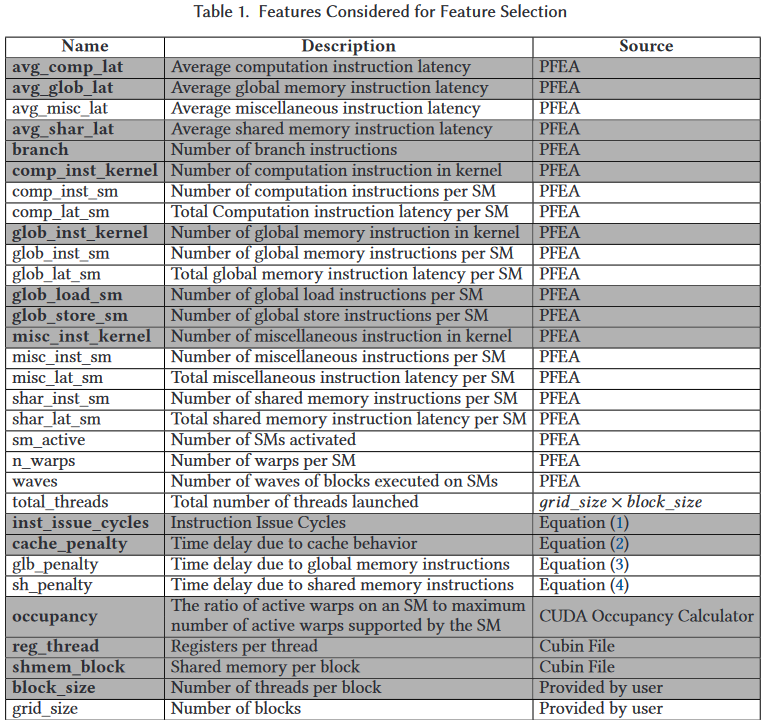
Q: Pseudo Algorithm : Goal is : Create power prediction model for CUDA kernel without execution: We can either use the cuda code as input, We can use PTX code from compiled binaries, Or we can use SASS code from compiled binaries, ( PTX, is an intermediate language. PTX is then compiled into a specific NVidia assembly language (often called SASS, though each SASS for each generation of cards is different).)
Algorithm: CUDA Binary Feature Extraction Input: CUDA binary file Output: Extracted features
-
Parse the CUDA binary: a. Use cuobjdump to extract SASS (Shader Assembly) code: cuobjdump -sass <input_file> > sass_output.txt
b. Use nvdisasm to get a more detailed disassembly with control flow information: nvdisasm <input_file> > nvdisasm_output.txt
-
Initialize feature counters and data structures:
- instruction_count = 0
- compute_instruction_count = 0
- memory_instruction_count = 0
- control_flow_instruction_count = 0
- register_usage = set()
- max_register_used = 0
- memory_operations = {‘global_load’: 0, ‘global_store’: 0, ‘shared_load’: 0, ‘shared_store’: 0}
-
Parse the SASS output (sass_output.txt): For each line in sass_output.txt: a. Increment instruction_count b. Classify the instruction and update counters: - If instruction is FADD, FMUL, FFMA, IADD, IMAD, etc.: increment compute_instruction_count - If instruction is LDG, STG, LDS, STS, etc.: increment memory_instruction_count Update memory_operations based on the specific operation - If instruction is BRA, JMP, CALL, RET, etc.: increment control_flow_instruction_count increment branch_count c. Extract register usage: - For each register Rx mentioned in the instruction: Add x to register_usage set Update max_register_used if x > max_register_used
-
Parse the nvdisasm output (nvdisasm_output.txt) for additional information: a. Extract basic block information b. Build a control flow graph c. Identify loops and their nesting levels
-
Calculate derived features: a. instruction_mix = compute_instruction_count / instruction_count b. memory_intensity = memory_instruction_count / instruction_count c. branch_intensity = branch_count / instruction_count d. avg_basic_block_size = instruction_count / number_of_basic_blocks e. register_pressure = len(register_usage) f. max_register_used = max(register_usage)
-
Extract kernel configuration information: Use cuobjdump -elf <input_file> to get ELF information Parse the output to find: a. grid_size b. block_size c. shared_memory_size d. local_memory_size
-
Estimate theoretical occupancy: Use the CUDA Occupancy Calculator API with the extracted kernel configuration
-
Analyze memory access patterns: a. Identify coalesced vs. non-coalesced memory accesses b. Detect bank conflicts in shared memory accesses
-
Identify potential performance issues: a. High register pressure (if register_pressure is close to architecture limit) b. Divergent branching (look for predicated instructions) c. Low occupancy (based on theoretical occupancy calculation) d. Unbalanced instruction mix (e.g., too many memory operations compared to compute)
-
Extract any constant memory usage: Look for instructions accessing constant memory (e.g., LDC)
-
Identify use of special functions: Look for MUFU (multi-function unit) instructions
-
Detect use of atomic operations: Count ATOM instructions
-
Analyze shared memory usage: a. Identify shared memory allocation size b. Detect potential bank conflicts
-
Estimate computational intensity: Ratio of compute instructions to memory instructions
-
Compile all extracted and calculated features into a structured output format (e.g., JSON)
-
Can use NVBIT (SASSI is deprecated) to instrument binaries in case we need a mapping
Notes: Use PTX as IR instead of SASS, empirical eval needs to be first handled, can start at app level, compiler pass,
Question: Types of metric: Answer:
When analyzing PTX (Parallel Thread Execution) code, there are numerous metrics that can be extracted and considered, both programmatically and architecturally. These metrics provide insights into the performance, resource utilization, and behavior of CUDA kernels. Here’s a detailed expansion on the types of metrics that can be extracted from PTX:
-
Instruction-level Metrics:
- Instruction count: Total number of PTX instructions
- Instruction mix: Distribution of different instruction types (arithmetic, logic, memory, control flow, etc.)
- Special instruction usage: Count of special functions (sin, cos, sqrt, etc.)
- Predicated instruction count: Number of instructions executed conditionally
-
Memory-related Metrics:
- Global memory accesses: Count of load/store operations to global memory
- Shared memory accesses: Count of load/store operations to shared memory
- Local memory usage: Amount of local memory allocated per thread
- Texture memory accesses: Count of texture fetch operations
- Memory coalescing potential: Analysis of memory access patterns
-
Control Flow Metrics:
- Branch instructions: Count of branch instructions (conditional and unconditional)
- Divergent branch potential: Identification of branches that may cause thread divergence
- Loop structures: Identification and analysis of loop constructs
-
Thread and Block Level Metrics:
- Thread count: Number of threads per block
- Block dimensions: Size and shape of thread blocks
- Grid dimensions: Size and shape of the grid
-
Register Usage:
- Register count: Number of registers used per thread
- Register pressure: Analysis of register utilization and potential spilling
-
Parallelism Metrics:
- Instruction-level parallelism (ILP): Potential for parallel execution of instructions
- Thread-level parallelism (TLP): Utilization of available threads
- Memory-level parallelism (MLP): Potential for overlapping memory operations
-
Synchronization and Communication:
- Barrier synchronizations: Count of __syncthreads() or equivalent operations
- Atomic operations: Count and types of atomic operations used
-
Computational Intensity:
- Arithmetic intensity: Ratio of compute operations to memory operations
- FLOPs (Floating Point Operations): Count of floating-point operations
-
Data Type Usage:
- Precision analysis: Usage of different precision types (float, double, half)
- Integer vs. floating-point operations: Distribution of integer and floating-point computations
-
Function-level Metrics:
- Function call count: Number of function calls (device functions)
- Function complexity: Analysis of function size and structure
-
Architectural-specific Features:
- Use of warp-level primitives: Count of warp shuffle, vote, or reduction operations
- Tensor Core usage: Identification of matrix multiply-accumulate operations
- Ray tracing instruction usage (for RTX GPUs)
-
Power and Performance Indicators:
- Instruction throughput potential: Estimation based on instruction mix
- Memory bandwidth utilization: Estimation based on memory access patterns
- Occupancy potential: Analysis of resource usage that affects occupancy
-
Code Size Metrics:
- PTX code size: Total size of the PTX code
- Basic block size distribution: Analysis of code structure
-
Optimization Opportunities:
- Loop unrolling potential: Identification of loops that could benefit from unrolling
- Shared memory bank conflict potential: Analysis of shared memory access patterns
- Instruction reordering opportunities: Identification of instruction sequences that could be optimized
-
Warp-level Metrics:
- Warp divergence potential: Analysis of control flow that may cause warp divergence
- Warp execution efficiency: Estimation of how efficiently warps are utilized
-
Latency Hiding Potential:
- Instruction-level latency hiding: Analyzing the potential for overlapping long-latency instructions with other instructions
- Memory latency hiding: Assessing the potential for overlapping memory accesses with computations
-
Instruction Dependency Analysis:
- Data dependencies: Identifying dependencies between instructions that may limit parallelism
- Control dependencies: Analyzing dependencies caused by control flow instructions
-
Instruction Scheduling Opportunities:
- Instruction reordering: Identifying opportunities to reorder instructions for better performance
- Instruction fusion: Analyzing potential for fusing multiple instructions into a single operation
-
Kernel Launch Configuration:
- Occupancy analysis: Determining the optimal thread block size and grid size for maximum occupancy
- Resource-based launch configuration: Analyzing the impact of shared memory, registers, and block size on occupancy
-
Memory Access Patterns:
- Strided access analysis: Identifying strided memory access patterns that may impact performance
- Memory access coalescing: Analyzing the potential for coalescing memory accesses for better bandwidth utilization
-
Divergence Analysis:
- Branch divergence: Analyzing the impact of branch divergence on warp execution efficiency
- Predicate usage: Assessing the effectiveness of predicate usage for controlling thread execution
-
Synchronization Overhead:
- Barrier synchronization overhead: Analyzing the impact of synchronization points on performance
- Atomic operation overhead: Assessing the overhead introduced by atomic operations
-
Workload Balancing:
- Thread workload distribution: Analyzing the distribution of work among threads within a block
- Block-level load balancing: Assessing the balance of work distribution across thread blocks
-
Occupancy Limiters:
- Shared memory usage: Analyzing how shared memory allocation affects occupancy
- Register usage: Assessing the impact of register usage on occupancy
-
Instruction Cache Analysis:
- Instruction cache misses: Estimating the potential for instruction cache misses based on kernel size and structure
- Instruction cache efficiency: Analyzing the effectiveness of instruction caching
-
Bank Conflict Analysis:
- Shared memory bank conflicts: Identifying potential bank conflicts in shared memory accesses
- Global memory bank conflicts: Analyzing potential bank conflicts in global memory accesses
-
Warp Scheduler Efficiency:
- Warp scheduler utilization: Assessing how efficiently the warp scheduler is being utilized
- Warp stall analysis: Identifying reasons for warp stalls (data dependencies, memory latency, etc.)
-
Instruction Mix Optimization:
- Instruction mix balance: Analyzing the balance between compute, memory, and control flow instructions
- Instruction throughput optimization: Identifying opportunities to improve instruction throughput
-
Kernel Complexity Metrics:
- Cyclomatic complexity: Measuring the complexity of the control flow graph
- Kernel size: Analyzing the size of the kernel in terms of instructions and basic blocks
-
PTX Optimization Opportunities:
- PTX-level optimization potential: Identifying PTX-specific optimization opportunities
- PTX-to-SASS translation efficiency: Analyzing how efficiently PTX is translated to SASS (Streaming Assembler)
Question: Another polished list of metrics:
Answer:
Here is an improved and extended list of metrics that can be extracted from PTX code using static analysis, based on the PTX documentation:
-
Instruction Metrics:
- Total instruction count
- Instruction type distribution (arithmetic, logic, control flow, memory access, etc.)
- Floating-point instruction count (single-precision and double-precision)
- Integer instruction count
- Control flow instruction count (branches, jumps, calls, etc.)
- Special instruction count (sin, cos, sqrt, etc.)
- Predicated instruction count
- Instruction level parallelism (ILP)
-
Memory Access Metrics:
- Global memory load/store count
- Shared memory load/store count
- Local memory load/store count
- Texture memory load count
- Constant memory load count
- Memory access patterns (coalescable, strided, random, etc.)
- Potential for memory access coalescing
- Potential for bank conflicts in shared memory
- Shared memory usage per thread block
-
Register Usage Metrics:
- Number of registers used per thread
- Register spilling count (if applicable)
- Register pressure analysis
-
Thread and Block Metrics:
- Number of threads per block
- Number of thread blocks
- Block dimensions (1D, 2D, or 3D)
- Grid dimensions (1D, 2D, or 3D)
- Thread divergence within warps
- Potential for warp divergence
-
Synchronization Metrics:
- Barrier synchronization count (e.g., __syncthreads())
- Atomic operation count
-
Function Metrics:
- Number of device functions called
- Function call depth
- Recursive function calls
-
Warp-level Operations:
- Warp shuffle instruction count
- Warp vote function count
- Warp reduction operation count
-
Kernel Launch Configuration Metrics:
- Occupancy analysis based on shared memory usage, register usage, and block size
- Recommended thread block size and grid size for optimal occupancy
-
Performance Metrics:
- Theoretical floating-point operations per second (FLOPS)
- Theoretical memory bandwidth utilization
- Computation-to-memory access ratio
- Potential for instruction-level parallelism (ILP)
- Potential for thread-level parallelism (TLP)
-
Code Complexity Metrics:
- Cyclomatic complexity of the control flow graph
- Kernel size in terms of PTX instructions
- Number of basic blocks
- Nesting depth of control flow structures
-
Optimization Opportunities:
- Loop unrolling candidates
- Instruction reordering opportunities
- Redundant instruction elimination
- Constant folding and propagation
-
PTX-specific Metrics:
- PTX version used
- Target architecture (e.g., sm_xx)
- Use of PTX-specific features (e.g., CUDA Dynamic Parallelism, Tensor Cores)
- PTX assembly size
-
Memory Hierarchy Utilization:
- L1 cache utilization
- L2 cache utilization
- Shared memory utilization
- Texture cache utilization
-
Data Type Metrics:
- Usage of different data types (int, float, double, etc.)
- Precision analysis (e.g., ratio of single-precision to double-precision)
-
Inter-thread Communication Metrics:
- Shared memory usage for inter-thread communication
- Use of warp-level primitives for communication (e.g., shuffle, vote)
-
Kernel Launch Overhead Metrics:
- Number of kernel launches
- Argument passing overhead
-
Branch Divergence Metrics:
- Number of divergent branches
- Percentage of threads taking the divergent path
- Impact of branch divergence on warp execution efficiency
-
Memory Access Efficiency Metrics:
- Cache hit ratio
- Memory bandwidth utilization
- Memory access latency
-
Instruction Execution Efficiency Metrics:
- Instruction replay overhead
- Stall reasons (memory dependencies, branch resolution, etc.)
-
Concurrent Kernel Execution Metrics:
- Number of concurrent kernels
- Resource utilization of concurrent kernels
Question: Combined polished list:
Answer: Here’s the combined list with all the metrics and their details:
-
Instruction-level Metrics:
- Instruction count: Total number of PTX instructions
- Instruction mix: Distribution of different instruction types (arithmetic, logic, memory, control flow, etc.)
- Special instruction usage: Count of special functions (sin, cos, sqrt, etc.)
- Predicated instruction count: Number of instructions executed conditionally
- Floating-point instruction count (single-precision and double-precision)
- Integer instruction count
- Control flow instruction count (branches, jumps, calls, etc.)
- Instruction level parallelism (ILP)
- Vector instruction usage (e.g., .v2, .v4 operations)
- Tensor Core instruction usage (mma, wmma instructions)
-
Memory-related Metrics:
- Global memory accesses: Count of load/store operations to global memory (ld.global, st.global)
- Shared memory accesses: Count of load/store operations to shared memory (ld.shared, st.shared)
- Local memory usage: Amount of local memory allocated per thread (ld.local, st.local)
- Texture memory accesses: Count of texture fetch operations (tex instructions)
- Memory coalescing potential: Analysis of memory access patterns
- Constant memory access count (ld.const)
- Unified memory usage (System-scoped memory operations)
- Cache operation usage (e.g., .ca, .cg, .cs, .lu cache hints)
-
Control Flow Metrics:
- Branch instructions: Count of branch instructions (conditional and unconditional) (bra, brx.idx)
- Divergent branch potential: Identification of branches that may cause thread divergence (based on predicated execution)
- Loop structures: Identification and analysis of loop constructs
- Function call count (call instructions)
- Predicate usage analysis
-
Thread and Block Level Metrics:
- Thread count: Number of threads per block (from kernel parameters)
- Block dimensions: Size and shape of thread blocks (inferred from special registers)
- Grid dimensions: Size and shape of the grid (inferred from special registers)
- Cluster dimension usage (for newer architectures)
-
Register Usage:
- Register count: Number of registers used per thread
- Register pressure: Analysis of register utilization and potential spilling
- Special register usage (e.g., %tid, %ntid, %laneid)
-
Parallelism Metrics:
- Instruction-level parallelism (ILP): Potential for parallel execution of instructions
- Thread-level parallelism (TLP): Utilization of available threads
- Memory-level parallelism (MLP): Potential for overlapping memory operations
- Warp-level parallelism analysis
-
Synchronization and Communication:
- Barrier synchronizations: Count of __syncthreads() or equivalent operations (bar.sync, barrier instructions)
- Atomic operations: Count and types of atomic operations used
- Memory fence operations (membar, fence instructions)
- Warp shuffle instruction usage
-
Computational Intensity:
- Arithmetic intensity: Ratio of compute operations to memory operations
- FLOPs (Floating Point Operations): Count of floating-point operations
- Integer vs. floating-point operation distribution
-
Data Type Usage:
- Precision analysis: Usage of different precision types (float, double, half) (.f16, .f32, .f64, .bf16)
- Integer vs. floating-point operations: Distribution of integer and floating-point computations
- Integer type usage (.s8, .s16, .s32, .s64, .u8, .u16, .u32, .u64)
- Bit-size type usage (.b8, .b16, .b32, .b64)
-
Function-level Metrics:
- Function call count: Number of function calls (device functions)
- Function complexity: Analysis of function size and structure (instruction count, control flow complexity)
- Function parameter analysis
- Device function vs. kernel function analysis
-
Architectural-specific Features:
- Use of warp-level primitives: Count of warp shuffle, vote, or reduction operations (vote, match, redux instructions)
- Tensor Core usage: Identification of matrix multiply-accumulate operations (mma, wmma instructions)
- Ray tracing instruction usage (for RTX GPUs)
- Independent thread scheduling usage
- Asynchronous copy instructions usage (cp.async)
-
Power and Performance Indicators:
- Instruction throughput potential: Estimation based on instruction mix
- Memory bandwidth utilization: Estimation based on memory access patterns
- Occupancy potential: Analysis of resource usage that affects occupancy
-
Code Size Metrics:
- PTX code size: Total size of the PTX code
- Basic block size distribution: Analysis of code structure
- Instruction density (instructions per byte of PTX)
-
Optimization Opportunities:
- Loop unrolling potential: Identification of loops that could benefit from unrolling
- Shared memory bank conflict potential: Analysis of shared memory access patterns
- Instruction reordering opportunities: Identification of instruction sequences that could be optimized
- Constant folding and propagation potential
-
Warp-level Metrics:
- Warp divergence potential: Analysis of control flow that may cause warp divergence
- Warp execution efficiency: Estimation of how efficiently warps are utilized
- Warp-synchronous programming patterns
-
Latency Hiding Potential:
- Instruction-level latency hiding: Analyzing the potential for overlapping long-latency instructions with other instructions
- Memory latency hiding: Assessing the potential for overlapping memory accesses with computations through instruction scheduling
-
Instruction Dependency Analysis:
- Data dependencies: Identifying dependencies between instructions that may limit parallelism (data dependency chains)
- Control dependencies: Analyzing dependencies caused by control flow instructions
-
Instruction Scheduling Opportunities:
- Instruction reordering: Identifying opportunities to reorder instructions for better performance
- Instruction fusion: Analyzing potential for fusing multiple instructions into a single operation
-
Kernel Launch Configuration:
- Occupancy analysis: Determining the optimal thread block size and grid size for maximum occupancy based on shared memory usage, register usage, and block size
- Resource-based launch configuration: Analyzing the impact of shared memory, registers, and block size on occupancy
-
Memory Access Patterns:
- Strided access analysis: Identifying strided memory access patterns that may impact performance
- Memory access coalescing: Analyzing the potential for coalescing memory accesses for better bandwidth utilization
-
Divergence Analysis:
- Branch divergence: Analyzing the impact of branch divergence on warp execution efficiency
- Predicate usage: Assessing the effectiveness of predicate usage for controlling thread execution
-
Synchronization Overhead:
- Barrier synchronization overhead: Analyzing the impact of synchronization points on performance
- Atomic operation overhead: Assessing the overhead introduced by atomic operations
-
Workload Balancing:
- Thread workload distribution: Analyzing the distribution of work among threads within a block
- Block-level load balancing: Assessing the balance of work distribution across thread blocks
-
Occupancy Limiters:
- Shared memory usage: Analyzing how shared memory allocation affects occupancy
- Register usage: Assessing the impact of register usage on occupancy
-
Instruction Cache Analysis:
- Instruction cache misses: Estimating the potential for instruction cache misses based on kernel size and structure
- Instruction cache efficiency: Analyzing the effectiveness of instruction caching
-
Bank Conflict Analysis:
- Shared memory bank conflicts: Identifying potential bank conflicts in shared memory accesses
- Global memory bank conflicts: Analyzing potential bank conflicts in global memory accesses
-
Warp Scheduler Efficiency:
- Warp scheduler utilization: Assessing how efficiently the warp scheduler is being utilized
- Warp stall analysis: Identifying reasons for warp stalls (data dependencies, memory latency, etc.)
-
Instruction Mix Optimization:
- Instruction mix balance: Analyzing the balance between compute, memory, and control flow instructions
- Instruction throughput optimization: Identifying opportunities to improve instruction throughput
-
Kernel Complexity Metrics:
- Cyclomatic complexity: Measuring the complexity of the control flow graph
- Kernel size: Analyzing the size of the kernel in terms of instructions and basic blocks
- Number of basic blocks
- Nesting depth of control flow structures
-
PTX Optimization Opportunities:
- PTX-level optimization potential: Identifying PTX-specific optimization opportunities
- PTX-to-SASS translation efficiency: Analyzing how efficiently PTX is translated to SASS (Streaming Assembler)
- PTX version used
- Target architecture (e.g., sm_xx)
-
Memory Hierarchy Utilization:
- L1 cache utilization
- L2 cache utilization
- Shared memory utilization
- Texture cache utilization
- Texture cache utilization potential
-
Inter-thread Communication Metrics:
- Shared memory usage for inter-thread communication
- Use of warp-level primitives for communication (e.g., shuffle, vote)
-
Kernel Launch Overhead Metrics:
- Number of kernel launches
- Argument passing overhead
-
Memory Access Efficiency Metrics:
- Cache hit ratio
- Memory bandwidth utilization
- Memory access latency
-
Instruction Execution Efficiency Metrics:
- Instruction replay overhead
- Stall reasons (memory dependencies, branch resolution, etc.)
-
Concurrent Kernel Execution Metrics:
- Number of concurrent kernels
- Resource utilization of concurrent kernels
-
PTX-specific Features:
- Use of state spaces (.global, .shared, .local, etc.)
- Directive usage (.minnctapersm, .maxntid, etc.)
-
Error Detection and Exception Handling:
- Use of saturation arithmetic
- NaN and infinity handling in floating-point operations
-
Dynamic Parallelism:
- Usage of CUDA Dynamic Parallelism features
-
Cooperative Groups:
- Usage of cooperative group synchronization
-
Asynchronous Operations:
- Usage of asynchronous copy operations
- Asynchronous barrier patterns
-
Tensor Memory Access Patterns:
- Usage of tensor memory access instructions
-
Matrix Multiply Accumulate (MMA) Operations:
- Frequency and types of MMA operations
Question: Details on creating a static analyzer to extract these metrics: Answer:
-
PTX Code Generation:
- Use NVIDIA’s nvcc compiler to generate PTX code from CUDA kernels.
- Command: nvcc -ptx your_kernel.cu -o your_kernel.ptx
-
Parsing PTX Code:
- Develop a parser to read and analyze the PTX code.
- You can use existing parsing libraries like ANTLR or write a custom parser.
-
Metrics Extraction: Focus on these key areas that affect compute, memory, and power consumption:
a) Instruction-level Metrics:
- Count and categorize instructions (arithmetic, logic, memory, control flow)
- Identify special instructions (sin, cos, sqrt) which are computationally expensive
- Analyze vector and tensor core instructions
b) Memory-related Metrics:
- Count global, shared, and local memory accesses
- Analyze memory coalescing potential
- Identify cache operation usage
c) Control Flow Metrics:
- Analyze branch instructions and divergence potential
- Identify loop structures
d) Thread and Block Level Metrics:
- Extract thread and block dimensions
e) Register Usage:
- Count registers used per thread
f) Parallelism Metrics:
- Estimate instruction-level, thread-level, and memory-level parallelism
g) Synchronization and Communication:
- Count barrier synchronizations and atomic operations
h) Computational Intensity:
- Calculate arithmetic intensity (compute ops / memory ops)
- Count floating-point operations
-
Implementation Approach: a) Lexical Analysis:
- Tokenize the PTX code into meaningful elements (instructions, operands, etc.)
b) Syntactic Analysis:
- Parse the tokenized code to understand its structure
c) Semantic Analysis:
- Analyze the parsed code to extract relevant metrics
d) Data Flow Analysis:
- Track data dependencies and flow to understand memory access patterns and parallelism potential
e) Control Flow Analysis:
- Build a control flow graph to analyze branching and loop structures
-
Power Consumption Estimation:
- While exact power consumption is hardware-dependent, you can create a model based on:
- Instruction mix (compute vs. memory operations)
- Memory access patterns (coalesced vs. non-coalesced)
- Parallelism utilization
- Register and shared memory usage
- While exact power consumption is hardware-dependent, you can create a model based on:
-
Challenges and Considerations:
- PTX is an intermediate representation, so some high-level optimizations might not be visible
- The relationship between PTX metrics and actual GPU performance/power consumption is complex
- Different GPU architectures may behave differently for the same PTX code
-
Tools and Libraries:
- Consider using existing tools like NVIDIA’s nvprof or Nsight Compute for validation
- Libraries like LLVM can be helpful for code analysis and transformation
-
Output and Visualization:
- Generate reports with extracted metrics
- Create visualizations (e.g., heat maps for memory access patterns, graphs for control flow)
-
Validation:
- Compare your static analysis results with dynamic profiling tools
- Test on a variety of CUDA kernels to ensure robustness
Question: What’s the best way to Develop a parser to read and analyze the PTX code. I want suggestion of solutions so that I can extend the analyzer easily to other representations, scripts, languages, etc
Answer: To develop a parser for PTX code that can be easily extended to other representations, scripts, and languages, I recommend using a modular and flexible approach. Here’s a suggested solution:
-
Use a parser generator or parsing library: Consider using tools like ANTLR, Bison, or recursive descent parsing libraries. These provide a structured way to define grammar rules and generate parsers.
-
Define a modular architecture: Create a base parser class that can be extended for different languages:
class BaseParser:
def __init__(self):
self.metrics = {}
def parse(self, code):
raise NotImplementedError
def get_metrics(self):
return self.metrics
class PTXParser(BaseParser):
def parse(self, code):
# Implement PTX-specific parsing logic
pass
class SASSParser(BaseParser):
def parse(self, code):
# Implement SASS-specific parsing logic
pass- Implement a flexible metric collection system: Use a plugin-based approach for metric collection:
class MetricCollector:
def __init__(self):
self.collectors = []
def register_collector(self, collector):
self.collectors.append(collector)
def collect_metrics(self, parsed_data):
metrics = {}
for collector in self.collectors:
metrics.update(collector.collect(parsed_data))
return metrics
class InstructionCountCollector:
def collect(self, parsed_data):
# Count instructions
pass
class MemoryAccessCollector:
def collect(self, parsed_data):
# Analyze memory accesses
pass- Use a visitor pattern for analysis: Implement a visitor pattern to separate analysis logic from the parsed structure:
class PTXVisitor:
def visit_instruction(self, instruction):
pass
def visit_basic_block(self, basic_block):
pass
class InstructionAnalyzer(PTXVisitor):
def visit_instruction(self, instruction):
# Analyze instruction
pass
class ControlFlowAnalyzer(PTXVisitor):
def visit_basic_block(self, basic_block):
# Analyze control flow
pass- Implement a flexible output system: Create a modular output system that can generate different formats:
class OutputGenerator:
def generate(self, metrics):
raise NotImplementedError
class JSONOutputGenerator(OutputGenerator):
def generate(self, metrics):
# Generate JSON output
pass
class CSVOutputGenerator(OutputGenerator):
def generate(self, metrics):
# Generate CSV output
pass- Main analysis pipeline:
def analyze_code(code, parser, metric_collector, output_generator):
parsed_data = parser.parse(code)
metrics = metric_collector.collect_metrics(parsed_data)
return output_generator.generate(metrics)
# Usage
ptx_parser = PTXParser()
metric_collector = MetricCollector()
metric_collector.register_collector(InstructionCountCollector())
metric_collector.register_collector(MemoryAccessCollector())
output_generator = JSONOutputGenerator()
result = analyze_code(ptx_code, ptx_parser, metric_collector, output_generator)This modular approach allows you to:
- Easily add new parsers for different languages or representations.
- Add or modify metric collectors without changing the core parsing logic.
- Implement different analysis strategies using the visitor pattern.
- Generate output in various formats by adding new output generators.
To extend this system to other representations or languages:
- Create a new parser class (e.g.,
CUDAParser) inheriting fromBaseParser. - Implement language-specific visitors if needed.
- Add any new metric collectors specific to the language.
- Use the existing analysis pipeline with the new components.
This architecture provides a flexible foundation that can be easily extended to handle various types of code analysis tasks across different GPU programming models and representations.
Citations: [1] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/1401754/d1f2998f-500b-420d-92ad-96807b2293b8/paste-2.txt [2] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/1401754/0acfafa7-1130-4bf8-946f-aa1864801db5/paste-2.txt [3] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/1401754/314a1fb3-0031-4bdf-a270-f1a835c8a858/paste.txt
Question: I want to make this tool scale to be used in actual real world scenarios, industrial use cases, users, and researchers, and also want to extent it further for various scenarios, like architecture, hardware, languages, representations, etc. What is the approach in design, implementation, i should take, and what would be the best formfactor to create and distribute the tool Answer: To create a scalable, extensible tool for real-world industrial use cases and research scenarios, you should consider the following approach in design and implementation:
-
Modular Architecture:
- Use a plugin-based architecture to allow easy extension of functionality.
- Implement a core engine with well-defined interfaces for different components.
- Separate concerns: parsing, analysis, optimization, code generation, etc.
-
Extensible Parsing:
- Implement a flexible parsing system that can handle multiple languages and representations.
- Consider using parser combinators or a parser generator that supports extensible grammars.
- Allow users to define custom grammars or extend existing ones.
-
Intermediate Representation (IR):
- Design a flexible IR that can represent various languages and hardware targets.
- Make the IR extensible to accommodate new language features or hardware capabilities.
-
Analysis and Optimization Framework:
- Create a pass manager for running different analyses and optimizations.
- Allow users to define custom passes and integrate them into the framework.
-
Code Generation:
- Implement a flexible code generation system that can target multiple architectures.
- Use a template-based approach or LLVM-style backend for easier extension to new targets.
-
Configuration and Customization:
- Provide a robust configuration system (e.g., YAML or JSON-based) for users to customize tool behavior.
- Allow users to define custom rules, heuristics, and policies.
-
API Design:
- Create a well-documented, stable API for programmatic access to the tool’s functionality.
- Provide language bindings for popular programming languages (e.g., Python, Java, C++).
-
Scalability:
- Implement parallel processing capabilities for handling large codebases.
- Use efficient data structures and algorithms to ensure good performance.
- Consider distributed computing capabilities for very large-scale analyses.
-
Visualization and Reporting:
- Integrate visualization capabilities for analysis results and metrics.
- Provide customizable reporting features for different user needs.
-
Testing and Validation:
- Implement a comprehensive test suite covering various use cases.
- Provide benchmarking tools for performance evaluation.
-
Documentation and Examples:
- Create thorough documentation, including API references, user guides, and tutorials.
- Provide example plugins and extensions to guide users in customizing the tool.
-
Community and Ecosystem:
- Establish a plugin repository or marketplace for sharing extensions.
- Encourage community contributions and provide guidelines for submitting extensions.
For distribution and form factor, consider the following:
-
Open-source Core:
- Release the core functionality as open-source to encourage adoption and community contributions.
-
Commercial Extensions:
- Offer premium features or industry-specific extensions as commercial add-ons.
-
Cloud-based Service:
- Provide a cloud-based version for easy access and scalability.
-
Desktop Application:
- Offer a standalone desktop application for users who prefer local installations.
-
Command-line Interface:
- Provide a CLI for integration into existing workflows and scripts.
-
IDE Plugins:
- Develop plugins for popular IDEs to integrate the tool directly into development environments.
-
Containerization:
- Offer Docker containers for easy deployment and consistent environments.
-
Package Managers:
- Distribute through popular package managers for different platforms (e.g., pip, npm, apt).
By following this approach, you can create a versatile, extensible tool that can adapt to various scenarios, architectures, hardware, languages, and representations while meeting the needs of industrial users and researchers alike.
Citations: [1] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/1401754/d1f2998f-500b-420d-92ad-96807b2293b8/paste-2.txt [2] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/1401754/0acfafa7-1130-4bf8-946f-aa1864801db5/paste-2.txt [3] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/1401754/314a1fb3-0031-4bdf-a270-f1a835c8a858/paste.txt [4] https://theproductmanager.com/tools/best-user-interface-design-software/ [5] https://www.linkedin.com/advice/3/what-most-effective-design-patterns-improving-software-1uafc [6] https://www.bjmc.lu.lv/fileadmin/user_upload/lu_portal/projekti/bjmc/Contents/5_1_09_Saikunas.pdf [7] https://selleo.com/blog/how-does-modular-software-architecture-improve-scalability [8] https://tomassetti.me/chisel-an-open-source-method-for-parsers/ [9] https://licensespring.com/blog/glossary/what-is-software-distribution/ [10] https://www.devleader.ca/2023/09/07/plugin-architecture-design-pattern-a-beginners-guide-to-modularity/ [11] https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html : To create a working MVP (Minimum Viable Product) for PTX code analysis, following the given points, here’s a detailed plan:
-
Setup and Tools:
- Use Python as the primary language for rapid development.
- Install necessary tools:
pip install antlr4-python3-runtime pyyaml matplotlib networkx
-
Modular Architecture:
- Create a main
PTXAnalyzerclass as the core engine. - Implement plugin interfaces for parsers, analyzers, and output generators.
- Create a main
-
Extensible Parsing:
- Use ANTLR4 for parsing PTX code. ANTLR allows for easy grammar extension.
- Create a basic PTX grammar file (ptx.g4).
-
Intermediate Representation (IR):
- Design a simple IR using Python classes to represent PTX instructions and basic blocks.
-
Analysis Framework:
- Implement a basic pass manager for running analyses.
- Create sample analysis passes (e.g., instruction count, memory access patterns).
-
Configuration:
- Use YAML for configuration files.
-
API Design:
- Create a simple API for running analyses and accessing results.
Detailed Implementation Plan:
-
Project Structure:
ptx_analyzer/ ├── __init__.py ├── main.py ├── core/ │ ├── __init__.py │ ├── ptx_analyzer.py │ ├── parser.py │ ├── ir.py │ └── pass_manager.py ├── passes/ │ ├── __init__.py │ ├── instruction_count.py │ └── memory_access.py ├── output/ │ ├── __init__.py │ └── console_output.py ├── grammars/ │ └── PTX.g4 └── config.yaml -
Implement Core Components:
a. PTX Grammar (grammars/PTX.g4):
grammar PTX; ptxFile : line+ ; line : instruction | label | directive ; instruction : opcode operand (',' operand)* ';' ; // Add more grammar rules...b. Parser (core/parser.py):
from antlr4 import * from .PTXLexer import PTXLexer from .PTXParser import PTXParser class PTXParserWrapper: def parse(self, input_string): input_stream = InputStream(input_string) lexer = PTXLexer(input_stream) stream = CommonTokenStream(lexer) parser = PTXParser(stream) return parser.ptxFile()c. Intermediate Representation (core/ir.py):
class Instruction: def __init__(self, opcode, operands): self.opcode = opcode self.operands = operands class BasicBlock: def __init__(self, instructions): self.instructions = instructionsd. Pass Manager (core/pass_manager.py):
class PassManager: def __init__(self): self.passes = [] def add_pass(self, analysis_pass): self.passes.append(analysis_pass) def run_passes(self, ir): results = {} for analysis_pass in self.passes: results[analysis_pass.name] = analysis_pass.run(ir) return resultse. PTX Analyzer (core/ptx_analyzer.py):
from .parser import PTXParserWrapper from .pass_manager import PassManager class PTXAnalyzer: def __init__(self): self.parser = PTXParserWrapper() self.pass_manager = PassManager() def analyze(self, ptx_code): parsed_code = self.parser.parse(ptx_code) ir = self.convert_to_ir(parsed_code) return self.pass_manager.run_passes(ir) def convert_to_ir(self, parsed_code): # Convert parsed code to IR pass -
Implement Sample Passes:
a. Instruction Count (passes/instruction_count.py):
class InstructionCountPass: name = "instruction_count" def run(self, ir): counts = {} for block in ir: for instruction in block.instructions: counts[instruction.opcode] = counts.get(instruction.opcode, 0) + 1 return countsb. Memory Access (passes/memory_access.py):
class MemoryAccessPass: name = "memory_access" def run(self, ir): accesses = {"load": 0, "store": 0} for block in ir: for instruction in block.instructions: if instruction.opcode.startswith("ld"): accesses["load"] += 1 elif instruction.opcode.startswith("st"): accesses["store"] += 1 return accesses -
Implement Output Generator:
a. Console Output (output/console_output.py):
class ConsoleOutput: def generate(self, results): for pass_name, pass_results in results.items(): print(f"{pass_name}:") for key, value in pass_results.items(): print(f" {key}: {value}") -
Main Script (main.py):
from core.ptx_analyzer import PTXAnalyzer from passes.instruction_count import InstructionCountPass from passes.memory_access import MemoryAccessPass from output.console_output import ConsoleOutput import yaml def main(): with open('config.yaml', 'r') as config_file: config = yaml.safe_load(config_file) analyzer = PTXAnalyzer() analyzer.pass_manager.add_pass(InstructionCountPass()) analyzer.pass_manager.add_pass(MemoryAccessPass()) with open(config['input_file'], 'r') as ptx_file: ptx_code = ptx_file.read() results = analyzer.analyze(ptx_code) output_generator = ConsoleOutput() output_generator.generate(results) if __name__ == "__main__": main() -
Configuration (config.yaml):
input_file: "path/to/your/ptx/file.ptx"
This MVP provides a foundation for PTX code analysis with a modular architecture. It uses ANTLR for parsing, implements a simple IR, includes a basic pass manager, and provides sample analysis passes. The configuration is handled through a YAML file, and results are output to the console.
To run the MVP:
- Install the required dependencies.
- Generate the ANTLR parser from the PTX grammar.
- Place your PTX file in the specified location in the config.yaml file.
- Run the main.py script.
This structure allows for easy extension by adding new passes, implementing different output formats, or enhancing the IR as needed. As you develop further, you can add more sophisticated analyses, implement visualization features, and expand the API for more complex use cases.
Citations: [1] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/1401754/d1f2998f-500b-420d-92ad-96807b2293b8/paste-2.txt [2] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/1401754/0acfafa7-1130-4bf8-946f-aa1864801db5/paste-2.txt [3] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/1401754/314a1fb3-0031-4bdf-a270-f1a835c8a858/paste.txt
Question: Idea’s - Building upon this work, there are several potential ideas and directions you could explore to create a novel profiler or expand the existing approach. Here are some suggestions:
-
Incorporate Dynamic Analysis: The current approach relies solely on static analysis of the PTX code and program features. While this provides a valuable compile-time perspective, combining it with dynamic analysis techniques could yield more accurate and comprehensive insights. You could explore ways to integrate runtime profiling data, such as performance counter readings or hardware event traces, to capture the dynamic behavior of the application and its impact on power consumption.
-
Develop a Hybrid Approach: Instead of relying solely on machine learning models, you could investigate a hybrid approach that combines analytical models with machine learning techniques. Analytical models based on architectural simulations or first-principles could capture the low-level hardware behaviors, while machine learning models could learn the complex interactions and non-linearities present in the data.
-
Explore Other Machine Learning Techniques: While the paper explores various ensemble methods and tree-based models, you could investigate the applicability of other advanced machine learning techniques, such as deep learning or graph neural networks. These techniques might be able to capture more intricate patterns and relationships within the data, potentially improving the prediction accuracy further.
-
Incorporate Compiler Optimizations: The current approach assumes a fixed PTX code representation. You could explore ways to incorporate compiler optimizations or code transformations into the analysis. By analyzing the impact of different optimization levels or specific transformations on power consumption, you might be able to provide optimization recommendations or even develop an optimization framework tailored for power efficiency.
-
Consider Multi-GPU Systems: The current work focuses on single GPU analysis. You could extend the approach to handle multi-GPU systems, where the power consumption dynamics might be different due to factors like inter-GPU communication, load balancing, and resource contention. Developing models that can accurately predict power consumption in multi-GPU environments would be valuable for large-scale HPC systems.
-
Incorporate Memory Access Patterns: While the current approach considers global and shared memory instructions, you could explore ways to incorporate more detailed memory access patterns into the analysis. This could include capturing coalescing behavior, bank conflicts, or cache locality patterns, which can have a significant impact on power consumption.
-
Develop a User-friendly Interface: To make the profiler more accessible and user-friendly, you could develop a graphical user interface (GUI) or integrate it with existing development environments or profiling tools. This would allow developers to easily analyze and optimize their applications for power efficiency without needing to delve into the intricacies of the underlying models or analysis techniques.
-
Explore Transfer Learning: If you plan to extend the approach to other GPU architectures or programming models (e.g., OpenCL, HIP), you could investigate transfer learning techniques. By leveraging the knowledge gained from the existing models, you might be able to adapt and fine-tune the models for new architectures or programming models more efficiently, reducing the need for extensive retraining or data collection.
-
Integrate Energy-Aware Optimizations: Building upon the power consumption predictions, you could explore ways to automatically optimize or refactor the CUDA code for better energy efficiency. This could involve techniques like kernel fusion, memory access pattern optimization, or even algorithmic transformations, guided by the insights provided by the profiler.
-
Develop Energy-Aware Scheduling: In a multi-application or multi-user environment, you could leverage the power consumption predictions to develop energy-aware scheduling strategies for GPU resources. By considering the power profiles of individual applications or kernels, you might be able to optimize resource allocation and workload distribution to minimize overall power consumption or achieve specific energy efficiency targets.
In details 9 and 10th:
-
Integrate Energy-Aware Optimizations:
a. Kernel Fusion: Analyze the power consumption predictions for individual kernels and identify opportunities for kernel fusion. If two or more kernels exhibit similar power consumption patterns and operate on the same data, you could explore techniques to fuse them into a single kernel. This can potentially reduce the overhead of kernel launches and data transfers, leading to energy savings.
b. Memory Access Pattern Optimization: Leverage the insights from the power consumption predictions related to global memory access patterns. Identify kernels with high global memory access penalties and explore techniques to optimize memory coalescing, reduce bank conflicts, or improve cache locality. This could involve code transformations, data layout changes, or algorithmic modifications.
c. Algorithmic Transformations: Analyze the power consumption hotspots in the code and explore alternative algorithmic implementations or data structures that could potentially reduce power consumption. For example, if a specific computation pattern is identified as power-intensive, you could investigate more energy-efficient algorithms or data structures to perform the same computation.
d. Compiler-based Optimizations: Develop a power-aware compiler or optimization framework that can automatically apply energy-efficient code transformations based on the power consumption predictions. This could involve techniques like loop unrolling, instruction scheduling, or register allocation optimizations tailored for power efficiency.
e. Profiling and Iterative Refinement: Implement a iterative process where you profile the optimized code, analyze the power consumption, and refine the optimizations based on the new insights. This iterative approach can help you continuously improve the energy efficiency of the code.
-
Develop Energy-Aware Scheduling:
a. Power Profiling: Leverage the power consumption predictions to create power profiles for individual kernels or applications. These profiles should capture the power consumption characteristics, resource requirements, and execution patterns of the workloads.
b. Resource Modeling: Develop a resource model that captures the power consumption characteristics of the GPU hardware, including the impact of resource contention, frequency scaling, and other factors that affect power consumption.
c. Scheduling Algorithms: Investigate scheduling algorithms that can take into account the power profiles of workloads and the resource model to optimize resource allocation and workload distribution. This could involve techniques like power-aware job packing, power-aware task mapping, or power-aware frequency scaling.
d. Multi-Objective Optimization: Explore multi-objective optimization techniques that can balance power consumption with other objectives such as performance, fairness, or quality of service. This could involve techniques like evolutionary algorithms, genetic algorithms, or multi-objective optimization frameworks.
e. Runtime System Integration: Develop a runtime system or scheduler that can integrate the energy-aware scheduling algorithms and dynamically adjust resource allocation and workload distribution based on the power consumption predictions and actual runtime measurements.
f. Validation and Evaluation: Validate the energy-aware scheduling strategies using real-world workloads and benchmarks. Evaluate the power savings, performance impact, and other relevant metrics to quantify the effectiveness of the proposed approaches.
-
Develop a Compiler-integrated Optimization Framework:
- Integrate the power prediction model into a compiler framework to enable automated code optimizations for energy efficiency.
- Develop techniques for power-aware code transformations, such as kernel fusion, memory access pattern optimization, or instruction scheduling.
- Explore the use of iterative compilation techniques, where the code is optimized, profiled, and iteratively refined based on the power consumption predictions.
In both cases, collaboration with domain experts, such as GPU architects, compiler developers, or scheduling researchers, would be beneficial. Additionally, access to detailed hardware specifications, power measurement tools, and representative workloads would be crucial for accurate modeling and realistic evaluations.
Q: Metrics used in current PTX parser: Answer: metric, its details, and how its calculated (in italics):
-
inst_issue_cycle: This feature represents the number of batches of instructions issued by the Fetch Decode Schedule (FDS) unit of the GPU. The FDS unit is responsible for issuing instructions to threads for execution, and it contributes significantly to the energy consumed by the GPU. A higher value of this feature indicates more instruction batches being issued, leading to higher power consumption. This is identified as the most crucial feature across all GPU architectures in the study, as the FDS unit is utilized by all instructions, making it a constant contributor to power consumption. It is computed using the formula: inst_issue_cycle = (total_threads / (nWS * warp_size)) * (total_inst / nDU), where total_threads is derived from the launch configuration, total_inst is calculated from the PFEA, nWS is the number of warp schedulers per SM, warp_size is the number of threads per warp, and nDU is the number of dispatch units per SM.
-
avg_comp_lat: This feature denotes the average latency of all computing instructions executed, including floating-point instructions like
fmadd,fadd,fmul,fdiv, andfma. Higher latency values for computing instructions indicate more power consumption, as the instructions take longer to execute. The paper suggests that applications constituting floating-point instructions contribute significantly to power consumption due to their higher latencies compared to integer computing instructions. The PFEA (Algorithm 1) accumulates the total latency for compute instructions (L(T(v))) by iterating over the instructions in the PTX code. The average latency is then calculated by dividing the total latency by the corresponding instruction count (I(T(v))). -
reg_thread: This feature represents the number of registers utilized per thread. Increased register usage leads to higher leakage power consumption, as register file size directly impacts power consumption. The paper suggests limiting the use of registers to build power-efficient applications. This feature is obtained from the .cubin file, which is generated from the CUDA source code.
-
glob_inst_kernel: This feature counts the number of global memory instructions in the kernel. Global memory instructions are identified as significant contributors to power consumption, as they involve accessing the off-chip DRAM, which is more power-intensive compared to on-chip memory accesses. The PFEA (Algorithm 1) accumulates the counts of global memory instructions (I(T(v))) by iterating over the instructions in the PTX code.
-
glob_store_sm: This feature specifically counts the number of global store instructions per Streaming Multiprocessor (SM). Global store instructions are found to be more power-consuming than global load instructions, as they involve writing data to the off-chip DRAM. The PFEA (Algorithm 1) accumulates the counts of global store instructions (N(i)) when encountered during the PTX code analysis.
-
avg_glob_lat: This feature represents the average latency of global memory instructions. Higher latencies for global memory instructions indicate longer execution times and, consequently, higher power consumption. The PFEA (Algorithm 1) accumulates the total latency for global memory instructions (L(T(v))) by iterating over the instructions in the PTX code. The average latency is then calculated by dividing the total latency by the corresponding instruction count (I(T(v))).
-
misc_inst_kernel: This feature counts the number of miscellaneous instructions in the kernel, such as synchronization (
sync), branch (bra), and return (ret) instructions. The PFEA (Algorithm 1) accumulates the counts of miscellaneous instructions (I(T(v))) by iterating over the instructions in the PTX code. -
cache_penalty: This feature quantifies the delay caused due to cache misses when accessing global memory. Cache misses lead to longer access times and higher power consumption, as data needs to be fetched from the off-chip DRAM. It is computed using the formula: cache_penalty = (total_threads * glob_inst_sm) / (waves * L2_sz / accesssz) * L(gm), where glob_inst_sm is the number of global memory instructions per SM from the PFEA, waves is the number of execution batches from the PFEA, L2_sz is the L2 cache size from device query, accesssz is the number of bytes accessed per memory instruction, and L(gm) is the latency of global memory instructions from micro-benchmarking.
-
avg_shar_lat: This feature represents the average latency of shared memory instructions. Shared memory is an on-chip memory shared among threads in a block, and its access latency contributes to power consumption, although to a lesser extent compared to global memory. The PFEA (Algorithm 1) accumulates the total latency for shared memory instructions (L(T(v))) by iterating over the instructions in the PTX code. The average latency is then calculated by dividing the total latency by the corresponding instruction count (I(T(v))).
-
occupancy: This feature measures the ratio of active warps (groups of threads executing concurrently) on an SM to the maximum number of active warps supported by the SM. Higher occupancy indicates better utilization of the GPU’s resources, leading to higher performance but potentially higher power consumption. This feature is not directly extracted but is calculated using the NVIDIA CUDA Occupancy Calculator, which takes into account the register usage (reg_thread), shared memory usage (shmem_block), and other architectural details.
-
shmem_block: This feature represents the amount of shared memory utilized per block (group of threads). Shared memory usage can impact power consumption, but its impact is relatively less significant compared to other features, according to the study. This feature is obtained from the .cubin file, which is generated from the CUDA source code.
-
branch: This feature counts the number of branch instructions in the kernel. Branch instructions can contribute to control flow divergence, which can impact power consumption due to the potential for thread divergence and underutilization of GPU resources. The PFEA (Algorithm 1) keeps track of the branch instruction count (N(i)) when encountered during the PTX code analysis.
-
glob_load_sm: This feature counts the number of global load instructions per SM. While global load instructions contribute to power consumption, their impact is found to be lesser compared to global store instructions. The PFEA (Algorithm 1) accumulates the counts of global load instructions (N(i)) when encountered during the PTX code analysis.
-
block_size: This feature represents the number of threads per block. The block size, along with the grid size (number of blocks), determines the total number of threads launched, which impacts power consumption. However, the study suggests that the block size itself is not as crucial as the total number of threads launched. This feature is provided by the user as a launch configuration parameter.
Todo , Question : Complete Microbenchmarking to get latency for instruction types, Should I also use CUDA code, and use tree-sitters grammar to parse and extract information from it? First priority is to make the PTX work
Question : What we need, predict PL, Are we creating, complete, comprehensive, (difference with current solution), feature selection.
Question: Research Questions for FlipFlop:
RQ1:
How can preemptive power limit optimization algorithms be developed to predict the optimal power limits for GPUs based on application characteristics and machine configurations? (And Validation : How can the preemptive power optimization framework be evaluated and validated on a diverse set of real-world applications and datasets?)
- What machine learning techniques can be used to train models for power limit prediction?
- How can online learning and adaptation be implemented to refine power limit predictions based on real-time feedback and historical data?
Including( Validation Below) - What experimental setup and evaluation methodology should be used to assess the effectiveness and scalability of the framework?
- How can the performance and power consumption of the optimized system be compared against baseline approaches and state-of-the-art techniques?
Extension/Combine:
How can machine-specific profiling be performed to gather relevant information about GPU architectures, memory hierarchies, and power management capabilities?
- How can machine-specific features and parameters be incorporated into the power prediction models?
- What techniques can be employed to profile and characterize the power consumption behavior of different GPU architectures and configurations?
RQ2: How can the optimal thread and block configurations be determined to maximize occupancy (this doesnt mean max perf or power, change wording of the RQs, memory insive tasks???) and achieve the best balance between parallelism and resource utilization for improved performance and power efficiency in GPU-based systems? Feedback :
Extension or Combined to choose the most apt/optimal combination of thread block that gives optimzal tradeoff between power and performance?
How can the trade-offs between power consumption and performance be analyzed and quantified when optimizing GPU power limits?
- What metrics and evaluation criteria should be used to assess the effectiveness of the power optimization framework?
- How can the impact of different power limit settings on application performance be measured and analyzed?
RQ3 (Depr):
How can the distributed power optimization framework be designed to ensure scalability and efficient resource management across multiple machines? / (How can a distributed architecture be designed to enable efficient communication and coordination between the central controller and individual machines for power optimization?) Feedback: This is a separate problem that can be a standalone alone Best to optimize individual kernel, GPU, lowest level rather than top or multi GPU’s
- What communication protocols and data exchange formats should be used?
- How can scalability and fault tolerance be ensured in the distributed setup?
- What strategies can be employed for workload distribution, load balancing, and power-aware scheduling?
- How can resource heterogeneity and dynamic provisioning be handled to optimize overall system performance and power efficiency?
Feedback: RQ1: what features are relevant/predictors should be first step- can be a standalone RQ?? Second Algorithm (what we have currently in RQ1 will be RQ2 now) - How can we apply this algorithm to a generalized env let’s say move it across GPU and validate-RQ3. Feature selection and algorihtm dopesnt need to be an AI model, have model instead () empriical model human extrcatiung features) : Check: https://dl.acm.org/doi/pdf/10.1145/1815961.1815998 Memory bandwidth e.g. doesn’t effect, ios constant, optimization has several local optima whiuch are equal , majority of them could be within a threshold eqwual to gloabl optima, multi objective optimization, several defined subproblems: how to optimize dvfs and pl to optimize performance, are there any lower level params taht can be easily chyanged like threrad block config, or even lopwer level like kernel specific, opti9mizinf back propogation kernel. take features and oiptimize perfoirnmace by optimizing thread block coinfiguration,
Additional RQs:
RQ6: What is the impact of dynamic voltage and frequency scaling (DVFS) techniques on the performance and power consumption of GPU workloads, and how can the optimal frequency and voltage settings be identified to achieve the best performance-power trade-off for a given workload?
RQ7: How does the choice of precision levels (e.g., single-precision vs. double-precision) and data types affect the performance and power consumption of GPU workloads, and what are the optimal precision and data type configurations that minimize memory bandwidth and storage requirements while maintaining acceptable accuracy?
RQ8: How can power gating and clock gating techniques be effectively utilized to reduce the power consumption of unused GPU components during periods of inactivity, and what are the potential benefits and trade-offs of employing these techniques in terms of performance and energy efficiency?
Q: Designing a Mathematical Model for Predicting CUDA Kernel Power Consumption Answer:
You can design a mathematical model that takes a CUDA kernel as input and predicts its power consumption based on the sources provided. Here’s a breakdown:
-
Model Inputs: The model would take a CUDA kernel as input. This would involve analyzing the kernel’s instructions to determine the usage of different GPU architectural components.
-
Power Consumption Components: Similar to the model described in the sources, your model would consider the following components of GPU power consumption:
- Dynamic Power: This refers to the power consumed during the active operation of the GPU’s components. You would model this based on the access rates of different architectural units like the Integer Arithmetic Unit, Floating Point Unit, Special Function Unit (SFU), ALU, register file, caches (texture, constant, shared), and memory units.
- Static Power: This refers to the power consumed even when the GPU is idle. You would need to incorporate the impact of temperature on static power, as leakage current, and hence static power, increases with temperature.
- Number of Active SMs: The number of active Streaming Multiprocessors (SMs) significantly impacts power consumption. You would need to model this based on the kernel’s execution characteristics, as the number of active SMs is not always equal to the total number of SMs available.
- Memory Access: You would need to account for power consumed by different memory spaces: global, shared, local, texture, and constant. This would involve analyzing the kernel’s memory access patterns.
-
Access Rate Prediction: As dynamic power consumption depends on the access rate of hardware components, your model would need a mechanism to predict these access rates. You could potentially achieve this by:
- Execution Time Prediction: Utilize a performance model like the MWP-CWP model (mentioned in source) or the one described in source to predict the kernel’s execution time.
- Instruction Analysis: Analyze the kernel’s instructions to estimate the number of accesses to each architectural component. You could use tools like the GPU PTX emulator (Ocelot) mentioned in source for this purpose.
-
Power Model Parameters: To accurately predict power consumption, your model would require parameters such as the maximum power consumption (MaxPower) of each architectural unit. You can derive these parameters empirically by designing microbenchmarks that stress specific architectural components and measuring their power consumption.
-
Temperature Modeling: To account for the impact of temperature on power consumption, you would need to integrate a temperature model. This model could be based on:
- Empirical Data: Measure the GPU temperature under different workloads and model the temperature rise and decay using equations similar to those presented in sources and.
- Relationship with Power and Memory Access: Consider the correlation between runtime power, memory access intensity, and chip temperature, as highlighted in source.
-
Optimal Number of Cores: While not explicitly predicting power consumption, you could enhance your model to determine the optimal number of active cores for achieving the best performance per watt.
Q: Build on top of KLARAPTOR: Answer:
Optimizing CUDA Kernels for Power: A Novel Research Study Building Upon KLARAPTOR
Your idea of building upon KLARAPTOR to create a static analyzer that optimizes CUDA kernels for power is interesting and has research potential. Here’s a potential research study design, leveraging the information from the sources and our conversation history:
Title: PowerKLARAPTOR: A Static Analysis Framework for Power-Aware Optimization of CUDA Kernels
1. Introduction
- Motivation: While KLARAPTOR effectively addresses performance optimization by tuning kernel launch parameters, modern GPU computing requires a shift towards considering power consumption as a primary optimization target, especially with growing concerns about energy efficiency and thermal constraints.
- Problem Statement: Existing tools lack the capability to statically analyze and optimize CUDA kernels for power efficiency.
- Proposed Solution: PowerKLARAPTOR will be a novel static analysis framework that extends KLARAPTOR’s capabilities by integrating a power model into its analysis. The framework will analyze CUDA source code and PTX (Parallel Thread Execution – a low-level parallel instruction set architecture) code to predict power consumption and identify opportunities for optimization.
2. Background and Related Work
- KLARAPTOR: Discuss the core concepts of KLARAPTOR, highlighting its use of the MWP-CWP performance model, rational program construction, and dynamic parameter selection (as detailed in our previous conversations).
- Power Modeling:
- Source provides insights into power modeling for GPUs. It explains how power consumption is divided into dynamic power (related to switching activity) and static power (leakage and other factors). You can utilize the power models and equations presented in this source as a foundation.
- Discuss existing power models for CPUs and GPUs and their limitations, particularly in the context of static analysis. Emphasize the need for a power model specifically tailored for CUDA kernels that considers factors like memory access patterns, thread block configuration, and GPU architectural features.
- Static Analysis for Power: Review existing static analysis techniques used for power optimization in the context of general-purpose programs and identify potential approaches that can be adapted for CUDA kernels.
3. PowerKLARAPTOR Framework Design
- Architecture:
- Input: CUDA source code, PTX code, Target GPU specifications (this could be obtained automatically if the target device is known).
- Components:
- PTX Code Analyzer: This component will analyze the PTX code to extract low-level information critical for power modeling, such as:
- Instruction mix (ratio of arithmetic, memory, control flow instructions)
- Memory access patterns (coalesced vs. uncoalesced, cache behavior)
- Thread synchronization and divergence patterns
- Power Model: This module will use the information extracted by the PTX Code Analyzer along with the target GPU’s specifications to estimate the power consumption of the CUDA kernel under various thread block configurations. The model should consider:
- Dynamic Power: Model this based on factors like the number of active warps, instruction types, memory access frequency, and any relevant architectural details impacting power (as hinted at in Source).
- Static Power: Account for the baseline power consumption of the GPU, which is influenced by temperature. You can adapt the temperature model presented in Source to incorporate temperature effects into your power estimation.
- Optimization Engine: This engine will utilize the power model to explore different thread block configurations and identify the configuration that minimizes power consumption while meeting performance constraints (as KLARAPTOR does with execution time). You could potentially use similar techniques to KLARAPTOR, like rational program construction, but adapt them for power optimization.
- PTX Code Analyzer: This component will analyze the PTX code to extract low-level information critical for power modeling, such as:
- Output: Optimized thread block configuration, Predicted power consumption, Potential code optimization suggestions (if any).
4. Methodology
- Power Model Development: This is a crucial aspect of the research.
- Benchmark Suite Selection: Select a diverse set of CUDA kernels from benchmarks like Polybench/GPU (used in Source) and others, ensuring a range of computational intensities and memory access patterns.
- Data Collection: Develop a profiling infrastructure (potentially extending KLARAPTOR’s existing profiler) to collect accurate power measurements for the selected benchmarks across different thread block configurations and input sizes. This might require tools that can measure GPU power consumption directly.
- Model Training and Validation: Utilize the collected data to train and validate your power model. Explore different model structures (linear regression, machine learning-based, or a combination) to determine the most accurate approach.
- Framework Implementation: Implement the PowerKLARAPTOR framework, integrating the power model with the code analysis and optimization components.
- Evaluation:
- Accuracy: Evaluate the accuracy of the power model by comparing its predictions with actual power measurements for a new set of unseen CUDA kernels and input sizes.
- Effectiveness: Measure the power savings achieved by PowerKLARAPTOR compared to using the original (non-optimized) thread block configurations and other existing optimization techniques.
- Overhead: Analyze the runtime overhead introduced by PowerKLARAPTOR’s analysis and optimization phases.
5. Expected Contributions
- A novel static analysis framework, PowerKLARAPTOR, for power-aware optimization of CUDA kernels.
- An accurate power model specifically designed for static analysis of CUDA kernels.
- Empirical evidence demonstrating the effectiveness of PowerKLARAPTOR in reducing the power consumption of CUDA kernels while maintaining performance.
6. Future Work
- Dynamic Voltage and Frequency Scaling (DVFS): Integrate DVFS techniques to dynamically adjust GPU clock speeds and voltages at runtime based on the kernel’s power and performance characteristics, further enhancing power savings.
- Code Optimization Suggestions: Explore techniques to provide programmers with code-level optimization suggestions that can further reduce power consumption, such as memory access pattern improvements or loop transformations.
- Multi-Objective Optimization: Develop algorithms that can optimize for both power and performance simultaneously, potentially allowing for trade-off analysis between these two objectives.
Additional Considerations:
- Collaboration with researchers who have expertise in GPU architecture, power modeling, and static analysis would be beneficial.
- Explore the possibility of integrating PowerKLARAPTOR into existing CUDA development environments to make it easily accessible to programmers.
Here are features that you can extract from CUDA source code and PTX code, which can then be used to build a power model:
CUDA Kernel Features for Power Modeling
- Instruction Mix: The ratio of different types of instructions (arithmetic, memory, control flow) in the PTX code can significantly impact power consumption.
- Arithmetic Instructions: These instructions typically consume less power compared to memory instructions.
- Memory Instructions: Accessing memory (global memory, shared memory) is a power-intensive operation. The frequency of memory instructions is a crucial factor in power modeling.
- Control Flow Instructions: Instructions related to branching and control flow can impact the predictability of execution, potentially affecting power consumption.
- Memory Access Patterns: Analyzing the PTX code can reveal memory access patterns, which are essential for accurate power modeling.
- Coalesced vs. Uncoalesced Memory Access: Coalesced memory accesses, where threads within a warp access contiguous memory locations, are more efficient and consume less power compared to uncoalesced accesses.
- Cache Behavior: The PTX code can provide insights into cache usage patterns (e.g., the number of cache hits and misses), which can influence power consumption.
- Thread Synchronization and Divergence: Analyzing thread behavior through the PTX code can help estimate power consumption.
- Synchronization: Frequent synchronization among threads can lead to stalls and increased power consumption.
- Divergence: When threads within a warp follow different execution paths, it can lead to serialization of instructions and potentially higher power use.
Additional Factors to Consider
- Target GPU Specifications: Hardware parameters of the target GPU are crucial inputs for power modeling:
- Memory Bandwidth: The available memory bandwidth of the GPU is a major factor influencing the power consumed during memory operations.
- Number of SMs and Clock Frequency: The number of Streaming Multiprocessors (SMs) and their operating clock frequency directly impact the power consumed by active cores.
- Other Architectural Features: Specific architectural details of the target GPU (cache sizes, memory access latencies, etc.) should be considered in your power model, as hinted at in the sources.
- Input Data Size: The size of the input data being processed by the CUDA kernel can influence memory access patterns, thread workload, and overall power consumption.
By extracting and analyzing these features from the CUDA source code and PTX code, you can build a comprehensive power model for your research study. The insights from [Source 1] on GPU power modeling will be valuable in guiding your model development.
Q: Mathematical Model? Answer:
Constructing a Mathematical Model for GPU Power Estimation
You can build a mathematical model for predicting GPU power consumption based on CUDA and PTX code by using statistical analysis techniques. The information from our conversation history and the sources provides a foundation for this:
1. Feature Extraction (from CUDA and PTX Code)
- Instruction Mix (Source): Analyze the PTX code to calculate the percentage of arithmetic instructions, memory instructions, and control flow instructions. These percentages can be represented as variables like
P_arithmetic,P_memory, andP_control. - Memory Access Type (Source): Determine the prevalence of coalesced versus uncoalesced memory accesses, potentially representing this as a ratio (
R_coalesced). This feature is crucial because coalesced accesses are more power-efficient. - Cache Miss Rate (Source): Although you mentioned using static analysis, estimating the precise cache miss rate statically might be challenging. However, you could potentially identify code segments with a high likelihood of cache misses (e.g., irregular access patterns) and incorporate a proxy variable (
P_cache_miss) for these segments. This might require dynamic analysis or profiling to establish a relationship between code patterns and actual cache miss rates for specific GPUs. - Thread Divergence (Source): Similar to cache miss rate, precisely quantifying thread divergence statically can be complex. You could develop heuristics to identify code regions prone to divergence (e.g., data-dependent branches within warps) and use a binary variable (
Div_flag) to indicate the presence or absence of such regions. - Number of Warps (Source): Extract the thread block dimensions (blockDim) from the CUDA code and the maximum threads per block (from the target GPU specifications) to calculate the number of active warps.
2. Incorporate Target GPU Features (Source)
- Memory Bandwidth (Source): Obtain this value from GPU specifications.
- SM Count and Clock Frequency (Source): Get these values from GPU specifications.
3. Model Structure
Since the exact relationships between these features and power consumption may not be linear, you can explore different model structures:
-
Linear Regression (Source):
- This model would assume a linear relationship between each feature and power consumption:
Power = β0 + β1 * P_arithmetic + β2 * P_memory + ... + βn * SM_count + ε- Where:
β0,β1, …,βnare coefficients to be estimated.- ε is the error term.
-
Polynomial Regression: To capture non-linear relationships, consider polynomial terms:
Power = β0 + β1 * P_arithmetic + β2 * P_arithmetic^2 + ... + βn * SM_count + ε -
Machine Learning Models (Source):
- Support Vector Regression, Random Forests, or Neural Networks: More complex models can capture intricate relationships, but require more data for training.
4. Data Collection (Source)
- Benchmark Suite: Choose a diverse set of CUDA kernels with varying characteristics (Polybench/GPU, Rodinia, etc.).
- Profiling: Develop a profiling tool or use existing ones (e.g., NVIDIA Nsight, Source) to collect power consumption data for different kernel executions.
5. Model Training and Validation (Source)
- Split Data: Divide the collected data into training and testing sets.
- Statistical Software: Utilize statistical software (R, Python with libraries like scikit-learn) to train the selected model structure on the training data.
- Coefficient Estimation: The software will estimate the model coefficients (
βvalues). - Model Validation: Evaluate the model’s performance on the testing data using metrics like R-squared, Mean Absolute Error (MAE), Root Mean Squared Error (RMSE).
6. Power Estimation
- Input: For a new CUDA kernel and target GPU, extract the features described in steps 1 and 2.
- Prediction: Use the trained model to predict the power consumption.
Challenges and Considerations
- Static vs. Dynamic Analysis: Accurately modeling features like cache miss rate and thread divergence might require dynamic profiling information or the development of highly sophisticated static analysis techniques.
- Data Requirements: Machine learning models require a substantial amount of training data for accurate predictions.
- GPU Architectural Variations: Power consumption can vary across different GPU architectures. Consider using a model that is either specific to an architecture or incorporates architectural features as input.
- Model Complexity and Interpretability: Complex models may provide higher accuracy but can be harder to interpret.
Q: Static Analysis Framework for Power-Aware Optimization of CUDA Kernels
Answer: As a GPU researcher, I’ll provide a more detailed and explicit description of the proposed study:
Title: A Comprehensive Static Analysis Framework for Power-Aware Optimization of CUDA Kernels
- Framework Development:
1.1 Static Analysis Passes:
- Develop an LLVM-based compiler front-end to parse CUDA code into an intermediate representation (IR)
- Implement the following analysis passes:
a) Memory access pattern analysis:
- Identify global, shared, and texture memory accesses
- Analyze coalescing patterns and bank conflicts
- Detect strided or random access patterns b) Computation intensity analysis:
- Calculate arithmetic intensity (operations per byte)
- Identify compute-bound vs memory-bound regions c) Control flow analysis:
- Detect thread divergence in conditional statements
- Analyze loop structures and iteration counts d) Resource utilization analysis:
- Estimate register usage per thread
- Analyze shared memory allocation
- Determine potential occupancy limitations
1.2 Power Modeling:
- Develop detailed power models for different GPU components:
a) Compute units (SMs):
- Model dynamic power based on instruction mix and execution count
- Account for clock gating and power gating effects b) Memory subsystem:
- Model DRAM power consumption based on access patterns
- Include power costs for L1/L2 caches and shared memory c) Interconnect:
- Model power consumption of on-chip networks d) Idle power:
- Account for static power consumption of inactive components
- Calibrate models using real power measurements on representative kernels
1.3 Optimization Heuristics:
- Develop a rule-based system to identify optimization opportunities:
a) Memory optimizations:
- Detect uncoalesced accesses and suggest reorganization
- Identify opportunities for shared memory usage b) Compute optimizations:
- Suggest loop unrolling or fusion based on arithmetic intensity
- Identify redundant computations for elimination c) Thread/warp optimizations:
- Detect divergent branches for potential reorganization
- Suggest optimal thread block configurations d) DVFS opportunities:
- Identify memory-bound regions for potential frequency scaling
- Power-Aware Optimizations:
2.1 Memory Optimizations:
- Implement source-to-source transformations for:
a) Global memory coalescing:
- Reorder array accesses to improve coalescing
- Introduce padding to avoid bank conflicts b) Shared memory utilization:
- Automatically introduce tiling for data reuse
- Optimize shared memory bank access patterns c) Texture memory utilization:
- Convert suitable global memory accesses to texture fetches
2.2 Compute Optimizations:
- Develop transformations for:
a) Loop optimizations:
- Implement loop unrolling with heuristics for unroll factor
- Perform loop fusion to increase arithmetic intensity b) Instruction-level optimizations:
- Replace expensive operations with faster alternatives
- Exploit special-function units (SFUs) where appropriate
2.3 Thread/Warp Optimizations:
- Implement:
a) Thread coarsening:
- Merge threads to reduce divergence and increase work per thread b) Warp specialization:
- Create specialized code paths for different warp behaviors c) Dynamic parallelism:
- Introduce child kernels for highly divergent code sections
2.4 Dynamic Voltage and Frequency Scaling:
- Develop a runtime system to: a) Dynamically adjust GPU clock frequencies based on kernel characteristics b) Implement fine-grained DVFS for different GPU components (compute, memory)
- Evaluation:
3.1 Benchmark Selection:
- Choose a diverse set of CUDA applications, including: a) Compute-intensive benchmarks (e.g., N-body simulations, FFT) b) Memory-intensive benchmarks (e.g., graph algorithms, sparse matrix operations) c) Mixed workloads (e.g., machine learning kernels, physics simulations)
- Include both regular and irregular workloads to test adaptability
3.2 Experimental Setup:
- Use multiple GPU architectures (e.g., NVIDIA Volta, Turing, Ampere)
- Employ high-precision power measurement tools (e.g., NVIDIA NVML, external power meters)
- Develop a comprehensive test harness for automated benchmarking
3.3 Metrics:
- Measure and report: a) Overall energy consumption (Joules) b) Average power consumption (Watts) c) Performance in terms of execution time and throughput d) Energy-Delay Product (EDP) to balance power and performance
3.4 Comparative Analysis:
- Compare against: a) Unoptimized kernels b) Manually optimized versions by expert programmers c) State-of-the-art CUDA compilers (e.g., NVIDIA nvcc with -O3) d) Existing power optimization techniques in the literature
- Analysis and Insights:
4.1 Quantitative Analysis:
- Perform statistical analysis of results: a) Calculate average, median, and distribution of power/energy savings b) Conduct sensitivity analysis for different optimization combinations c) Analyze correlations between kernel characteristics and optimization effectiveness
4.2 Qualitative Analysis:
- Provide detailed case studies for selected benchmarks: a) Explain which optimizations were applied and why b) Analyze the interplay between different optimizations c) Discuss any unexpected results or limitations encountered
4.3 Architectural Insights:
- Analyze how different GPU architectures respond to the optimizations
- Identify potential hardware improvements to better support power-aware optimizations
4.4 Limitations and Future Work:
- Discuss limitations of the static analysis approach
- Propose potential extensions, such as: a) Incorporating dynamic profiling information b) Exploring machine learning-based optimization selection c) Extending the framework to other parallel computing paradigms (e.g., OpenCL, HIP)
This detailed research plan provides a comprehensive approach to developing and evaluating a static analysis framework for power-aware optimization of CUDA kernels. The study covers all aspects from low-level analysis and modeling to high-level optimizations and thorough evaluation, aiming to advance the state-of-the-art in energy-efficient GPU computing.
More details about step 1 and 2:
As a GPU researcher, I’ll provide a more detailed and explicit description of how to implement the static analysis passes and power modeling components of the framework:
1.1 Static Analysis Passes:
Implementation of LLVM-based compiler front-end:
- Utilize Clang as the front-end to parse CUDA C/C++ code.
- Extend Clang to handle CUDA-specific syntax (e.g., global, shared keywords).
- Implement a custom CUDA to LLVM IR lowering pass to preserve CUDA-specific semantics.
a) Memory access pattern analysis:
- Implement a new LLVM pass that traverses the IR:
- Identify memory operations using LLVM’s LoadInst and StoreInst classes.
- Classify memory accesses based on CUDA address spaces (e.g., addrspace(1) for global memory).
- For each memory instruction:
- Analyze the address calculation to determine access patterns.
- Implement symbolic analysis to detect affine expressions in array indices.
- Coalescing analysis:
- Group memory accesses by warp (assume 32 threads per warp).
- Check if consecutive threads access consecutive memory locations.
- Bank conflict detection for shared memory:
- Analyze shared memory accesses within a thread block.
- Detect if multiple threads access the same bank (modulo 32 for current GPUs).
- Strided/random access detection:
- Use symbolic analysis to identify stride patterns in loop indices.
- Classify accesses as strided, sequential, or random based on the analysis.
b) Computation intensity analysis:
- Implement an instruction counting pass:
- Count arithmetic operations (using LLVM’s Instruction class).
- Count memory operations (LoadInst and StoreInst).
- Calculate arithmetic intensity:
- Ratio of arithmetic operations to memory operations.
- Classify kernel regions:
- Define thresholds for compute-bound vs memory-bound.
- Annotate IR with classification for each basic block.
c) Control flow analysis:
- Implement a branch analysis pass:
- Traverse LLVM’s BranchInst and SwitchInst instructions.
- Identify conditionals that depend on thread ID (divergent branches).
- Loop analysis:
- Utilize LLVM’s existing LoopInfo analysis pass.
- Extend it to analyze CUDA-specific loop patterns (e.g., grid-stride loops).
- Iteration count estimation:
- Use symbolic analysis to bound loop iteration counts where possible.
- Annotate loops with estimated iteration counts or symbolic expressions.
d) Resource utilization analysis:
- Register usage estimation:
- Implement a pass to count LLVM virtual registers.
- Map LLVM types to PTX register sizes for accurate estimation.
- Shared memory allocation analysis:
- Track allocas and global variables in shared address space.
- Sum up total shared memory usage per kernel.
- Occupancy calculation:
- Implement NVIDIA’s occupancy calculation algorithm.
- Use estimated register and shared memory usage as inputs.
- Annotate kernels with estimated occupancy information.
1.2 Power Modeling:
a) Compute units (SMs) power model:
- Develop an instruction-level power model:
- Profile individual PTX instructions on target GPUs using microbenchmarks.
- Create a lookup table of power costs for each instruction type.
- Implement a dynamic power estimation pass:
- Traverse LLVM IR, mapping instructions to profiled power costs.
- Accumulate total dynamic power based on instruction counts and types.
- Model clock and power gating effects:
- Analyze control flow to estimate idle cycles.
- Apply gating factors based on GPU architecture specifications.
b) Memory subsystem power model:
- DRAM power modeling:
- Implement Micron’s DRAM power model (or similar).
- Use memory access patterns from 1.1.a to estimate row buffer hit rates.
- Cache power modeling:
- Develop analytical models for L1/L2 cache power based on access patterns.
- Use CACTI or similar tools to estimate cache static and dynamic power.
- Shared memory power model:
- Model shared memory as a specialized cache structure.
- Account for bank conflicts in power estimation.
c) Interconnect power model:
- Develop a high-level model of the GPU’s on-chip network:
- Estimate wire lengths based on GPU die size and SM layout.
- Model routers and links using analytical power models.
- Estimate traffic patterns based on memory access analysis from 1.1.a.
- Calculate dynamic power based on estimated traffic and static power based on network size.
d) Idle power modeling:
- Measure base idle power for target GPUs using real hardware.
- Develop a componential model to distribute idle power among GPU units.
- Implement an idle power estimation pass:
- Analyze kernel utilization of different components.
- Scale idle power components based on utilization estimates.
Calibration process:
- Develop a set of microbenchmarks targeting specific GPU components.
- Measure actual power consumption using NVIDIA’s NVML API or external power meters.
- Implement a least-squares fitting algorithm to adjust model parameters:
- Minimize difference between estimated and measured power across benchmarks.
- Validate the calibrated model on a separate set of test kernels.
- Implement an automated calibration process for easy adaptation to new GPU architectures.
Implementation considerations:
- Use C++ for implementing LLVM passes and analysis algorithms.
- Leverage LLVM’s existing analysis passes where possible (e.g., LoopInfo, ScalarEvolution).
- Implement power models as separate modules for flexibility and reusability.
- Use CUDA driver API and NVML for runtime measurements and validation.
- Develop a comprehensive test suite for each analysis pass and power model component.
- Implement logging and visualization tools for debugging and result analysis.
This detailed implementation plan provides a roadmap for developing the static analysis passes and power modeling components of the framework. It covers the key algorithms, data structures, and tools needed to build a comprehensive power-aware optimization system for CUDA kernels.
Proof of concept using PTX instead of CLANG:
As a GPU researcher, I’ll provide a detailed, explicit plan for implementing a proof-of-concept static analysis framework for power-aware optimization of CUDA kernels using PTX:
Title: PTX-based Static Analysis Framework for Power-Aware Optimization of CUDA Kernels (Proof-of-Concept)
- PTX Generation and Parsing:
1.1 PTX Generation: a) Use NVIDIA’s nvcc compiler to generate PTX:
- Command: nvcc -ptx kernel.cu -o kernel.ptx b) Implement a Python script to automate PTX generation for multiple kernels:
- Input: Directory of .cu files
- Output: Corresponding .ptx files
1.2 PTX Parser Development: a) Implement a lexer using Python’s ‘re’ module:
- Define regular expressions for PTX instructions, registers, memory operations, etc.
- Example: instr_pattern = r’(\w+.\w+)\s+(.*?);’ b) Develop a parser to create an in-memory representation of the PTX:
- Create classes for Instructions, BasicBlocks, Functions
- Implement parsing logic for different instruction types (arithmetic, memory, control flow)
- Static Analysis Passes:
2.1 Memory Access Pattern Analysis: a) Implement a function to identify memory operations:
- Parse ld, st, atom instructions
- Classify as global, shared, or texture memory based on PTX syntax b) Analyze coalescing patterns:
- Track base addresses and offsets used in memory operations
- Check if consecutive threads access consecutive memory locations c) Detect strided/random access:
- Analyze address calculations in PTX
- Classify access patterns based on index calculations
2.2 Computation Intensity Analysis: a) Implement instruction counting:
- Count arithmetic operations (add, mul, div, etc.)
- Count memory operations (ld, st) b) Calculate arithmetic intensity:
- Ratio of arithmetic operations to memory operations c) Classify kernel regions:
- Define thresholds for compute-bound vs memory-bound
- Annotate basic blocks with classification
2.3 Control Flow Analysis: a) Implement branch analysis:
- Identify branching instructions (bra, brx)
- Detect predicates based on thread ID (divergent branches) b) Perform loop analysis:
- Identify back-edges in the control flow graph
- Estimate iteration counts where possible
2.4 Resource Utilization Analysis: a) Estimate register usage:
- Count unique registers used in the PTX b) Analyze shared memory allocation:
- Parse .shared directive in PTX c) Calculate occupancy:
- Use NVIDIA’s occupancy calculator API
- Input register and shared memory usage
- Simplified Power Modeling:
3.1 Instruction-level Power Model: a) Create a lookup table of estimated power costs for PTX instructions:
- Use published data or microbenchmarking results
- Example: power_costs = {‘add’: 1.0, ‘mul’: 1.2, ‘ld.global’: 2.5, …} b) Implement a function to estimate kernel power:
- Sum power costs for all instructions in the kernel
- Apply simple scaling factors for different GPU architectures
3.2 Memory Subsystem Power Estimation: a) Implement a basic DRAM power model:
- Estimate row buffer hit rate based on access patterns
- Apply different power costs for row hits vs misses b) Estimate cache power:
- Use a simplified analytical model based on cache accesses
3.3 Static Power Estimation: a) Use a constant factor for static power:
- Based on published data for target GPU architecture b) Scale static power by estimated kernel duration
- Optimization Suggestions:
4.1 Memory Optimization Suggestions: a) Implement heuristics to detect uncoalesced accesses:
- Suggest reordering or padding arrays b) Identify opportunities for shared memory usage:
- Detect repeated global memory accesses
4.2 Compute Optimization Suggestions: a) Suggest loop unrolling:
- Based on loop trip counts and register pressure b) Identify redundant computations:
- Look for repeated arithmetic operations on same operands
4.3 Thread/Warp Optimization Suggestions: a) Suggest thread coarsening:
- For kernels with low arithmetic intensity b) Propose warp specialization:
- For kernels with high branch divergence
- Validation and Evaluation:
5.1 Power Measurement: a) Use NVIDIA’s nvprof for power profiling:
- Command: nvprof —print-gpu-trace —metrics power kernel b) Implement a Python script to automate power measurements:
- Run kernels with various input sizes
- Collect and store power measurements
5.2 Accuracy Evaluation: a) Compare estimated power with measured power:
- Calculate percentage error
- Analyze correlation between estimates and measurements b) Evaluate optimization suggestions:
- Manually apply suggested optimizations
- Measure actual power savings
5.3 Benchmark Suite: a) Select a diverse set of CUDA kernels:
- Include compute-bound and memory-bound kernels
- Consider kernels from popular benchmark suites (e.g., Rodinia) b) Implement a test harness:
- Automate PTX generation, analysis, and power measurement
- Generate reports comparing estimated and measured power
- Implementation Details:
6.1 Software Architecture: a) Implement core functionality as Python modules:
- ptx_parser.py: PTX parsing logic
- static_analysis.py: Analysis passes
- power_model.py: Power estimation
- optimization_suggestor.py: Optimization heuristics b) Create a main driver script:
- Orchestrate the entire analysis pipeline
6.2 Data Structures: a) Implement a KernelRepresentation class:
- Store parsed PTX, analysis results, and power estimates b) Use NetworkX library for control flow graph representation
6.3 Visualization: a) Implement Matplotlib-based visualizations:
- Plot estimated vs measured power
- Visualize hotspots in kernels
6.4 Configuration and Extensibility: a) Use YAML for configuration files:
- Specify GPU architecture parameters
- Set analysis thresholds and heuristics b) Design the system for easy extension:
- Allow adding new analysis passes and optimization suggestions
This proof-of-concept implementation focuses on the core functionality using PTX as the input, providing a faster path to a working system. It can be iteratively improved and expanded based on initial results and insights gained from this prototypey
Q: Predict or estimate cores/transistors/SMs from a given code? Ans: Based on the search results and the information provided, predicting the exact number of transistors, cores, or streaming multiprocessors (SMs) a CUDA kernel will use is not straightforward. However, we can provide some insights on how to estimate resource usage:
- Streaming Multiprocessors (SMs): The number of SMs used depends on the kernel launch configuration and available hardware resources. For example:
- A V100 GPU has 80 SMs [4].
- The number of blocks that can run concurrently on an SM is limited by resources like registers and shared memory [4].
- You can estimate SM utilization based on your launch configuration and hardware limits.
- Cores: CUDA cores are part of SMs and are used to execute thread instructions:
- Each SM on a V100 has 64 CUDA cores [4].
- All cores within an active SM are typically utilized, but not necessarily at 100% efficiency.
- The actual core usage depends on factors like instruction mix and memory access patterns.
- Transistors: Predicting transistor usage for a specific kernel is extremely complex and not typically done at the application level. However:
- Modern GPUs have billions of transistors (e.g., NVIDIA’s B100 has 208 billion transistors) [2].
- Transistor count is more relevant for overall GPU design rather than individual kernel execution.
To estimate resource usage for your kernel:
- Use CUDA occupancy calculator to determine how many blocks and threads can run concurrently on an SM [4].
- Profile your kernel using tools like Nsight Compute to get insights into resource utilization [4].
- Consider factors like:
- Number of threads per block
- Register usage per thread
- Shared memory usage per block
- Total number of blocks launched
For example, if you launch a kernel with:
dim3 block(16,16,1);
dim3 grid(200);
kernel<<<grid, block>>>();
This launches 200 blocks with 256 threads each. On a V100:
- Total threads: 200 * 256 = 51,200
- Maximum resident threads per SM: 2048 [4]
- Theoretical maximum concurrent blocks: 80 SMs * 8 blocks/SM = 640 [4]
In this case, you’re utilizing less than 30% of the available resources, assuming no other limitations [4].
To get more accurate predictions:
- Use profiling tools to measure actual resource usage.
- Develop or use existing performance models that take into account factors like memory access patterns and instruction mix [1][2].
- Consider using simulation tools for more detailed analysis of kernel behavior [5].
Remember that actual resource utilization can vary based on many factors, including other kernels running concurrently and the specific GPU architecture.
Citations: [1] https://hal.science/hal-02924028/document [2] https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4640924/ [3] https://epochai.org/blog/predicting-gpu-performance [4] https://forums.developer.nvidia.com/t/get-the-number-of-cores-used-in-a-kernel-launch/108023 [5] https://www.osti.gov/biblio/1326472 [6] https://ir.lib.uwo.ca/cgi/viewcontent.cgi?article=12031&context=etd [7] https://faculty.cc.gatech.edu/~hyesoon/hong_isca10.pdf
Q: Static analyzer Answer: Creating a static analyzer to predict power consumption of a CUDA kernel is an ambitious and complex task. Based on the reference paper you provided (Hong and Kim’s “An Integrated GPU Power and Performance Model”), here’s an outline of how you could approach this:
-
Develop a Static Code Analyzer:
- Parse CUDA kernels to extract information about instruction types and counts.
- Analyze memory access patterns (global, shared, local, texture, constant).
- Estimate the number of threads and blocks that will be launched.
-
Create a Performance Model:
- Estimate execution time based on instruction counts and types.
- Consider memory bandwidth limitations and potential saturation points.
- Account for GPU architecture specifics (e.g., number of SMs, CUDA cores per SM).
-
Develop a Power Model:
- Break down power consumption into components (similar to Equation 7 in the paper):
- Integer arithmetic unit
- Floating point unit
- Special Function Unit (SFU)
- ALU
- Memory units (global, local, shared, texture, constant)
- Register file
- Fetch/Decode/Schedule unit
- Estimate access rates for each component based on instruction counts and estimated execution time.
- Break down power consumption into components (similar to Equation 7 in the paper):
-
Calibrate the Model:
- Run a set of benchmark kernels on actual hardware.
- Measure power consumption using tools like NVIDIA’s nvprof or third-party power meters.
- Adjust your model parameters to match real-world measurements.
-
Implement the Integrated Power and Performance (IPP) Prediction:
- Combine the performance and power models.
- Predict power consumption for different numbers of active SMs.
- Find the optimal number of SMs that maximizes performance per watt.
-
Validate and Refine:
- Test your model on a variety of CUDA kernels.
- Compare predictions with actual measurements.
- Continuously refine the model based on results.
Key Challenges:
- Accuracy of static analysis: Runtime behavior can be difficult to predict statically.
- Architectural details: Detailed knowledge of the GPU architecture is required.
- Calibration: Extensive testing and calibration will be needed for accurate predictions.
- Evolving hardware: The model will need updates for new GPU architectures.
Tools and Technologies:
- LLVM for static code analysis of CUDA kernels.
- CUDA Toolkit for compiling and analyzing CUDA code.
- Python or C++ for implementing the prediction model.
- Profiling tools like NVIDIA Nsight Compute for validation.
Remember that this is a complex research-level project. The paper you referenced represents significant work by researchers. Creating an accurate model will require extensive knowledge of GPU architectures, CUDA programming, and power modeling techniques.
Citations: [1] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/1401754/1fa4648a-c1b7-4473-b262-2c949cf324c8/1815961.1815998-1.pdf [2] https://www.yecl.org/publications/ma09hotpower.pdf [3] https://faculty.cc.gatech.edu/~hyesoon/hong_isca10.pdf [4] https://dl.acm.org/doi/pdf/10.1145/3649169.3649249 [5] https://www.osti.gov/biblio/1326472 [6] https://cogumbreiro.github.io/assets/verifying-verifiers-tfp23.pdf
Plot interpretation:
- Thread Scaling Analysis:
# Thread Scaling Plot
thread_groups = df.groupby('Threads')['GFLOPS'].mean()
axes[0,0].plot(thread_groups.index, thread_groups.values, 'o-', linewidth=2)
axes[0,0].set_xscale('log', base=2)
axes[0,0].set_yscale('log', base=2)How to interpret:
- X-axis: Number of threads (log2 scale)
- Y-axis: GFLOPS (log2 scale)
- Ideal scaling: Linear line in log-log plot (45° slope)
- Common patterns:
- Linear scaling: Performance doubles when threads double
- Sublinear scaling: Flattening curve indicates diminishing returns
- Saturation: Horizontal line shows resource limits reached
Performance ^ | Ideal / | / | / Actual | / ---- | / ---- |/---- +----------------> Threads
- Energy Efficiency Scaling:
energy_efficiency = df.groupby('Threads')['Energy_Efficiency'].mean()
axes[0,1].plot(energy_efficiency.index, energy_efficiency.values, 'o-')How to interpret:
- X-axis: Number of threads
- Y-axis: GFLOPS/Joule
- Look for:
- Peak efficiency point (optimal thread count)
- Diminishing returns
- Energy efficiency cliff (where adding threads hurts efficiency)
Efficiency ^ | Peak | /\ | / \ | / \ | / \ |/ \ +----------------> Threads
- Power vs Performance Trade-off:
axes[1,0].scatter(df['Power(W)'], df['GFLOPS'],
c=np.log2(df['Threads']), cmap='plasma')How to interpret:
- X-axis: Power consumption (W)
- Y-axis: Performance (GFLOPS)
- Color: Thread count (darker = more threads)
- Look for:
- Clusters indicating efficient configurations
- Power-performance sweet spots
- Diminishing returns in performance vs power
GFLOPS ^ | Sweet Diminishing | Spot Returns | *-------* | / | / | / | / | / |/ +----------------> Power (W)
- Memory Bandwidth Scaling:
memory_efficiency = df.groupby('Threads')['Memory_Efficiency'].mean()
axes[1,1].plot(memory_efficiency.index, memory_efficiency.values, 'o-')How to interpret:
- X-axis: Thread count
- Y-axis: GB/s/Watt
- Look for:
- Memory bandwidth saturation
- Optimal thread count for memory operations
- Memory bottlenecks
Bandwidth ^ | -------- | / | / | / | / | / | / | / |/ +----------------> Threads
Key Metrics to Analyze:
- Scaling Efficiency:
scaling_efficiency = (performance_increase / thread_increase)-
0.8: Good scaling
- 0.5-0.8: Moderate scaling
- <0.5: Poor scaling
- Energy Proportionality:
energy_prop = (performance_increase / power_increase)-
1: Energy efficient scaling
- <1: Energy inefficient scaling
- Memory Bandwidth Utilization:
bandwidth_utilization = actual_bandwidth / theoretical_peak-
80%: Good utilization
- 50-80%: Moderate utilization
- <50%: Poor utilization
Example Analysis:
def analyze_scaling_efficiency(df):
base_threads = df['Threads'].min()
base_perf = df[df['Threads'] == base_threads]['GFLOPS'].mean()
for threads in sorted(df['Threads'].unique()):
if threads == base_threads:
continue
current_perf = df[df['Threads'] == threads]['GFLOPS'].mean()
thread_scaling = threads / base_threads
perf_scaling = current_perf / base_perf
scaling_efficiency = perf_scaling / thread_scaling
print(f"Threads: {threads}")
print(f"Scaling Efficiency: {scaling_efficiency:.2f}")
print(f"Performance Improvement: {perf_scaling:.2f}x")
print("---")Making Decisions:
- Optimal Thread Count:
- Look for the point where performance scaling starts to flatten
- Consider energy efficiency peak
- Balance with memory bandwidth utilization
- Energy Optimization:
- Find configurations where energy efficiency increases faster than performance decreases
- Look for sweet spots in power-performance curve
- Resource Utilization:
- Identify bottlenecks (compute vs memory bound)
- Find optimal block sizes for your GPU architecture
Would you like me to provide more specific analysis techniques or additional metrics to consider? I’ll explain each plot and its interpretation in detail:
- Kernel-Specific Plots (
create_kernel_specific_plots):
# Plot 1: Power vs Threads
ax1.scatter(block_data['Threads'], block_data['Power(W)'])Interpretation:
- Shows how power consumption scales with thread count
- Log2 scale reveals exponential relationships
- Ideal: Sub-linear power increase with thread count
- Look for: Power efficiency cliffs
- Energy Efficiency Plot:
ax2.scatter(block_data['Threads'], block_data['Energy_Efficiency'])Interpretation:
- GFLOPS/Joule vs Thread count
- Higher is better
- Look for:
- Peak efficiency point
- Diminishing returns
- Optimal thread count
- Performance Analysis:
ax3.scatter(block_data['Threads'], block_data['GFLOPS'])Interpretation:
- Shows raw performance scaling
- Ideal: Linear scaling (45° line in log scale)
- Look for:
- Scaling bottlenecks
- Performance saturation points
- Energy-Time Trade-off:
ax4.scatter(df['Time(s)'], df['Energy(J)'])Interpretation:
- Shows performance-energy trade-off
- Color indicates GFLOPS
- Look for:
- Pareto optimal points
- Energy-time sweet spots
- Scaling Analysis (
create_scaling_analysis):
# Thread Scaling
thread_groups = df.groupby('Threads')['GFLOPS'].mean()Interpretation:
- Shows how performance scales with threads
- Ideal scaling: Doubling threads doubles performance
- Common patterns:
- Linear (ideal)
- Sub-linear (common)
- Saturation (resource limits)
- Efficiency Analysis (
create_efficiency_analysis):
# Energy Efficiency Distribution
sns.histplot(data=df, x='Energy_Efficiency')Key Metrics:
- Energy Efficiency: GFLOPS/Joule
- Performance per Watt: GFLOPS/Watt
- Memory Efficiency: GB/s/Watt
Scaling Interpretation:
# Calculate scaling efficiency
def analyze_scaling(df):
base_threads = df['Threads'].min()
base_perf = df[df['Threads'] == base_threads]['GFLOPS'].mean()
scaling_efficiency = []
for threads in sorted(df['Threads'].unique()):
perf = df[df['Threads'] == threads]['GFLOPS'].mean()
scaling = (perf/base_perf) / (threads/base_threads)
scaling_efficiency.append(scaling)
return scaling_efficiencyOptimal Configurations:
# Finding optimal configurations
metrics = {
'optimal_config': {
'threads': df.loc[df['Energy_Efficiency'].idxmax()]['Threads'],
'blocks': df.loc[df['Energy_Efficiency'].idxmax()]['Blocks']
}
}Decision Making:
-
Performance Optimization:
- Look for maximum GFLOPS
- Consider scaling efficiency
-
Energy Optimization:
- Look for maximum GFLOPS/Joule
- Consider energy-time trade-off
-
Memory Optimization:
- Look for maximum GB/s/Watt
- Consider bandwidth utilization
Example Analysis:
def analyze_configuration(df, threads, blocks):
config_data = df[(df['Threads'] == threads) & (df['Blocks'] == blocks)]
return {
'performance': config_data['GFLOPS'].mean(),
'energy_efficiency': config_data['Energy_Efficiency'].mean(),
'power_consumption': config_data['Power(W)'].mean(),
'memory_efficiency': config_data['Memory_Efficiency'].mean()
}Would you like me to elaborate on any specific aspect or provide more detailed analysis techniques?
Q: Operations: Answer: Let me explain the CUDA thread/block configurations and their relationship to hardware architecture:
- Thread Hierarchy:
- Thread: Smallest execution unit
- Block: Group of threads that can cooperate
- Grid: Collection of blocks
- Configurations:
1D Configuration:
dim3 block(256, 1, 1); // 256 threads in x dimension
dim3 grid((N + 255)/256, 1, 1); // N elements divided into blocks
- Best for: Vector operations, linear data
- Example uses: Vector addition, reduction
- Hardware mapping: Threads map directly to SIMD lanes
- Memory access: Good coalescing for sequential data
2D Configuration:
dim3 block(16, 16, 1); // 16x16 = 256 threads
dim3 grid((N + 15)/16, (N + 15)/16, 1); // NxN matrix
- Best for: Matrix operations, image processing
- Example uses: Matrix multiplication, convolution
- Hardware mapping: Maps well to 2D cache structures
- Memory access: Can optimize for 2D locality
3D Configuration:
dim3 block(8, 8, 8); // 8x8x8 = 512 threads
dim3 grid((N + 7)/8, (N + 7)/8, (N + 7)/8); // NxNxN volume
- Best for: Volume processing, 3D simulations
- Example uses: 3D convolution, fluid dynamics
- Hardware mapping: More complex scheduling
- Memory access: Challenging to optimize locality
Architectural Considerations:
- Hardware Limits:
- Max threads per block: Usually 1024
- Max dimensions: (1024, 1024, 64)
- Warp size: 32 threads
- SM (Streaming Multiprocessor) count: Varies by GPU
- Performance Factors:
- Memory coalescing: Adjacent threads should access adjacent memory
- Bank conflicts: Avoid multiple threads accessing same memory bank
- Occupancy: Balance between block size and resource usage
- Cache utilization: Consider L1/L2 cache line sizes
- Common Optimizations:
// Example of memory coalescing in 2D
__global__ void optimizedKernel(float* data, int width, int height) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int idy = blockIdx.y * blockDim.y + threadIdx.y;
// Coalesced access pattern
int globalIdx = idy * width + idx;
if(idx < width && idy < height) {
data[globalIdx] = process(data[globalIdx]);
}
}- Resource Trade-offs:
- Larger blocks: Better resource reuse, lower launch overhead
- Smaller blocks: Better load balancing, higher parallelism
- Shared memory vs registers: Balance based on algorithm needs
- Architecture-Specific Features:
// Example using shared memory in 2D block
__global__ void sharedMemKernel(float* data, int N) {
__shared__ float sharedData[BLOCK_SIZE][BLOCK_SIZE];
int tx = threadIdx.x;
int ty = threadIdx.y;
int bx = blockIdx.x;
int by = blockIdx.y;
// Collaborative loading into shared memory
sharedData[ty][tx] = data[(by * blockDim.y + ty) * N + (bx * blockDim.x + tx)];
__syncthreads();
// Process using fast shared memory access
// ...
}Would you like me to elaborate on any specific aspect of these configurations or architectural details?
Q: Answer: I’ll help you design a comprehensive study for creating a CUDA kernel power predictor and energy optimizer. Here’s a systematic approach:
- Feature Extraction and Analysis:
struct KernelFeatures {
// Static Features (from code analysis)
struct StaticFeatures {
int num_arithmetic_ops;
int num_memory_ops;
int num_control_flow_ops;
int register_pressure;
int shared_memory_usage;
float arithmetic_intensity; // FLOPs per byte
int instruction_mix[4]; // Distribution of instruction types
bool uses_atomic_ops;
bool uses_shared_memory;
bool uses_texture_memory;
float branch_divergence_potential;
};
// Dynamic Features (runtime)
struct DynamicFeatures {
float sm_occupancy;
float memory_throughput;
float cache_hit_rate;
int active_warps;
float memory_bandwidth_utilization;
float compute_utilization;
int memory_transactions;
int cache_transactions;
float warp_execution_efficiency;
};
// Configuration Features
struct ConfigFeatures {
int block_size;
int grid_size;
int shared_mem_per_block;
int registers_per_thread;
float theoretical_occupancy;
int active_blocks_per_sm;
};
};
// Power Model Components
struct PowerComponents {
float compute_power; // Compute unit power
float memory_power; // Memory system power
float static_power; // Static/idle power
float cache_power; // Cache system power
float interconnect_power; // NoC power
};- Data Collection Framework:
class PowerPredictor {
private:
// Feature collection
std::vector<float> collectStaticFeatures(const char* ptx_code) {
std::vector<float> features;
// Parse PTX code to extract static features
// Use NVCC/LLVM tools to analyze instruction mix
return features;
}
std::vector<float> collectDynamicFeatures(const void* kernel_func) {
std::vector<float> features;
// Use CUDA Profiler APIs to collect runtime metrics
return features;
}
// Power measurement and recording
struct PowerMeasurement {
double timestamp;
double power;
std::vector<float> features;
KernelConfig config;
};
std::vector<PowerMeasurement> power_measurements;
public:
void collectTrainingData(const void* kernel_func, const KernelConfig& config) {
// Start power monitoring
nvmlInit();
nvmlDevice_t device;
nvmlDeviceGetHandleByIndex(0, &device);
// Collect features and power measurements
auto static_features = collectStaticFeatures(getPTXCode(kernel_func));
auto dynamic_features = collectDynamicFeatures(kernel_func);
// Record measurements
PowerMeasurement measurement;
measurement.features.insert(
measurement.features.end(),
static_features.begin(), static_features.end());
measurement.features.insert(
measurement.features.end(),
dynamic_features.begin(), dynamic_features.end());
measurement.config = config;
power_measurements.push_back(measurement);
}
};- Energy Model Development:
class EnergyModel {
private:
// ML model parameters
struct ModelParameters {
std::vector<float> compute_weights;
std::vector<float> memory_weights;
std::vector<float> static_weights;
float bias;
};
ModelParameters params;
public:
// Power prediction function
float predictPower(const std::vector<float>& features) {
float compute_power = computeComponent(features, params.compute_weights);
float memory_power = memoryComponent(features, params.memory_weights);
float static_power = staticComponent(features, params.static_weights);
return compute_power + memory_power + static_power + params.bias;
}
// Energy optimization function
KernelConfig optimizeEnergy(const void* kernel_func,
const std::vector<KernelConfig>& possible_configs) {
float min_energy = std::numeric_limits<float>::max();
KernelConfig best_config;
for (const auto& config : possible_configs) {
auto features = collectFeatures(kernel_func, config);
float predicted_power = predictPower(features);
float estimated_time = estimateExecutionTime(features);
float energy = predicted_power * estimated_time;
if (energy < min_energy) {
min_energy = energy;
best_config = config;
}
}
return best_config;
}
};- Study Design and Analysis:
class EnergyStudy {
public:
void conductStudy() {
// 1. Feature Analysis
analyzeFeatureImportance();
// 2. Power Model Validation
validatePowerModel();
// 3. Energy Optimization Analysis
analyzeEnergyOptimization();
// 4. Report Generation
generateReport();
}
private:
void analyzeFeatureImportance() {
// Correlation analysis
computeFeatureCorrelations();
// Principal Component Analysis
performPCA();
// Feature selection
selectSignificantFeatures();
}
void validatePowerModel() {
// Cross-validation
std::vector<float> predictions;
std::vector<float> actual_measurements;
// Error analysis
float mse = computeMSE(predictions, actual_measurements);
float mae = computeMAE(predictions, actual_measurements);
// Model sensitivity analysis
analyzeModelSensitivity();
}
void analyzeEnergyOptimization() {
// Pareto frontier analysis
std::vector<std::pair<float, float>> power_performance_points;
computeParetoFrontier(power_performance_points);
// Configuration space exploration
exploreConfigurationSpace();
// Optimization strategy evaluation
evaluateOptimizationStrategies();
}
};
// Example usage
int main() {
// Initialize study
EnergyStudy study;
PowerPredictor predictor;
EnergyModel model;
// Register kernels for analysis
std::vector<KernelInfo> kernels = {
{"matmul", matrixMulKernel<float>},
{"convolution", convolutionKernel<float>},
{"reduction", reductionKernel<float>}
};
// Conduct study
for (const auto& kernel : kernels) {
// Collect training data
predictor.collectTrainingData(kernel.func, kernel.default_config);
// Train model
model.train(predictor.getTrainingData());
// Optimize configurations
auto optimal_config = model.optimizeEnergy(
kernel.func,
generatePossibleConfigs(kernel.type)
);
// Validate results
validateResults(kernel, optimal_config);
}
// Generate comprehensive report
study.conductStudy();
study.generateReport();
return 0;
}Key Components of the Study:
- Feature Selection:
- Static code analysis (instruction mix, memory access patterns)
- Dynamic runtime metrics (occupancy, cache behavior)
- Hardware configuration parameters
- Thermal and power characteristics
- Data Collection:
- Systematic sampling of different kernel configurations
- Power measurements using NVML
- Performance counter collection
- Temperature monitoring
- Model Development:
- Multiple regression analysis
- Machine learning models (Random Forests, Neural Networks)
- Cross-validation and error analysis
- Model sensitivity analysis
- Energy Optimization:
- Configuration space exploration
- Multi-objective optimization (power vs. performance)
- Dynamic adaptation strategies
- Constraint satisfaction (temperature, performance requirements)
- Validation and Analysis:
- Statistical significance testing
- Error analysis and model accuracy
- Performance impact assessment
- Energy savings quantification
This framework allows for:
- Systematic feature analysis
- Robust model development
- Comprehensive validation
- Practical optimization strategies
Let me know if you need more specific details about any component of this design.
I’ll help design a mathematically sound multi-objective optimization algorithm for CUDA kernel power and performance optimization.
// Multi-Objective Optimization Problem Definition
struct ObjectiveFunction {
// Primary Objectives
double energy; // E = P * t (Joules)
double performance; // T = t (seconds)
double power; // P (Watts)
double throughput; // R = ops/second
// Constraints
double temp_limit; // Tmax (°C)
double power_cap; // Pmax (Watts)
double perf_target; // Tmin (seconds)
};
// Mathematical Model Components
class PowerPerformanceModel {
private:
// Power Model: P(x) = Pstatic + Pdynamic(x)
double calculatePower(const std::vector<double>& x) {
// x: feature vector [f_clock, v_core, active_sms, mem_bandwidth, ...]
// P = Pstatic + α*f*V² + β*MB + γ*T
double f_clock = x[0];
double v_core = x[1];
double mem_bandwidth = x[2];
double temperature = x[3];
double P_static = c_static; // Static power constant
double P_dynamic = alpha * f_clock * std::pow(v_core, 2) +
beta * mem_bandwidth +
gamma * temperature;
return P_static + P_dynamic;
}
// Performance Model: T(x) = Tcompute(x) + Tmemory(x)
double calculateTime(const std::vector<double>& x) {
// T = (Compute_Intensity * Work_Items) / (f_clock * active_sms) +
// (Memory_Intensity * Data_Size) / mem_bandwidth
double f_clock = x[0];
double active_sms = x[2];
double mem_bandwidth = x[3];
double T_compute = (compute_intensity * work_items) /
(f_clock * active_sms);
double T_memory = (memory_intensity * data_size) / mem_bandwidth;
return std::max(T_compute, T_memory);
}
public:
// Pareto Optimization using ε-constraint method
std::vector<std::vector<double>> findParetoFrontier(
const std::vector<double>& x_init,
const std::vector<std::pair<double, double>>& bounds) {
std::vector<std::vector<double>> pareto_points;
// Initialize ε-constraint values
std::vector<double> epsilon_values = generateEpsilonValues();
for (double epsilon : epsilon_values) {
// Solve constrained optimization problem
auto result = minimizeEnergy(
x_init, bounds,
[epsilon](const std::vector<double>& x) {
return calculateTime(x) <= epsilon;
}
);
if (isValidSolution(result)) {
pareto_points.push_back(result);
}
}
return pareto_points;
}
};
// Multi-Objective Optimization using Weighted Sum Method
class WeightedSumOptimizer {
private:
// Objective function weights
struct Weights {
double w_energy;
double w_performance;
double w_thermal;
};
// Normalized objective function
double calculateObjective(const std::vector<double>& x, const Weights& w) {
double E_norm = normalize(calculateEnergy(x));
double T_norm = normalize(calculateTime(x));
double Th_norm = normalize(calculateTemperature(x));
return w.w_energy * E_norm +
w.w_performance * T_norm +
w.w_thermal * Th_norm;
}
public:
// Gradient descent optimization
std::vector<double> optimize(
const std::vector<double>& x_init,
const Weights& weights,
const Constraints& constraints) {
std::vector<double> x = x_init;
double learning_rate = 0.01;
double tolerance = 1e-6;
while (!converged(x, tolerance)) {
// Calculate gradient
auto gradient = calculateGradient(x, weights);
// Update solution
for (size_t i = 0; i < x.size(); ++i) {
x[i] -= learning_rate * gradient[i];
}
// Project onto feasible set
x = projectOntoConstraints(x, constraints);
}
return x;
}
};
// Augmented Lagrangian Method for Constrained Optimization
class AugmentedLagrangianOptimizer {
private:
// Lagrangian function
double calculateLagrangian(
const std::vector<double>& x,
const std::vector<double>& lambda,
double mu) {
double obj = calculateObjective(x);
double penalty = 0.0;
// Add constraint penalties
for (size_t i = 0; i < constraints.size(); ++i) {
double ci = constraints[i](x);
penalty += lambda[i] * ci + (mu/2) * ci * ci;
}
return obj + penalty;
}
public:
// Main optimization loop
std::vector<double> optimize(
const std::vector<double>& x_init,
const std::vector<Constraint>& constraints) {
std::vector<double> x = x_init;
std::vector<double> lambda(constraints.size(), 0.0);
double mu = 1.0;
while (!converged()) {
// Minimize Lagrangian
x = minimizeLagrangian(x, lambda, mu);
// Update multipliers
for (size_t i = 0; i < lambda.size(); ++i) {
lambda[i] += mu * constraints[i](x);
}
// Update penalty parameter
mu *= beta;
}
return x;
}
};
// Implementation of the complete optimization algorithm
class KernelEnergyOptimizer {
private:
PowerPerformanceModel model;
WeightedSumOptimizer wsm_optimizer;
AugmentedLagrangianOptimizer alm_optimizer;
// Kernel configuration space
struct ConfigSpace {
std::vector<double> clock_frequencies;
std::vector<double> block_sizes;
std::vector<double> grid_sizes;
std::vector<double> memory_configs;
};
public:
struct OptimalConfig {
std::vector<double> parameters;
double energy;
double performance;
double temperature;
};
OptimalConfig findOptimalConfig(
const KernelFeatures& features,
const Constraints& constraints,
const PreferenceWeights& weights) {
// 1. Initialize configuration space
auto config_space = initializeConfigSpace(features);
// 2. Generate initial solution
auto x_init = generateInitialSolution(config_space);
// 3. Multi-phase optimization
// Phase 1: Find Pareto frontier
auto pareto_points = model.findParetoFrontier(x_init, config_space);
// Phase 2: Weighted sum optimization
auto ws_solution = wsm_optimizer.optimize(
x_init, weights, constraints);
// Phase 3: Fine-tune with augmented Lagrangian
auto final_solution = alm_optimizer.optimize(
ws_solution, constraints);
// 4. Validate and return optimal configuration
return validateAndPackageResult(final_solution);
}
};
// Example usage
int main() {
// Initialize optimizer
KernelEnergyOptimizer optimizer;
// Define constraints
Constraints constraints{
.max_power = 250.0, // Watts
.max_temp = 85.0, // Celsius
.min_perf = 100.0 // GFLOPS
};
// Define preference weights
PreferenceWeights weights{
.energy = 0.5,
.performance = 0.3,
.thermal = 0.2
};
// Extract kernel features
KernelFeatures features = extractKernelFeatures(kernel_ptr);
// Find optimal configuration
auto optimal_config = optimizer.findOptimalConfig(
features, constraints, weights);
// Apply configuration
applyConfiguration(optimal_config);
return 0;
}This mathematical framework provides:
-
Multi-Objective Formulation:
- Minimizes energy: E(x) = P(x) * T(x)
- Maximizes performance: R(x) = 1/T(x)
- Subject to thermal and power constraints
-
Power Model: P(x) = Pstatic + αfV² + βMB + γT
- f: clock frequency
- V: voltage
- MB: memory bandwidth
- T: temperature
- α, β, γ: model coefficients
-
Performance Model: T(x) = max(Tcompute, Tmemory)
- Tcompute = (CI * W) / (f * SM)
- Tmemory = (MI * D) / MB
- CI: compute intensity
- MI: memory intensity
- W: work items
- SM: active SMs
- D: data size
-
Optimization Methods:
- Pareto frontier exploration using ε-constraint method
- Weighted sum method for preference-based optimization
- Augmented Lagrangian method for constraint handling
-
Constraint Handling:
- Power cap: P(x) ≤ Pmax
- Temperature limit: T(x) ≤ Tmax
- Performance requirement: R(x) ≥ Rmin
The algorithm provides:
- Mathematical soundness through proper formulation
- Multi-objective optimization capability
- Constraint satisfaction
- Practical applicability to CUDA kernels
Let me know if you need more specific details about any part of this mathematical framework.
I’ll explain how to implement this analysis framework using your current benchmark data:
- First, Create a Data Processing Pipeline
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
class BenchmarkDataProcessor:
def __init__(self):
self.scaler = StandardScaler()
self.feature_groups = {
'hardware': [
'sm_clock', 'mem_clock', 'temp',
'power_usage', 'fan_speed',
'memory_utilization', 'gpu_utilization'
],
'kernel_stats': [
'sm_occupancy', 'active_warps', 'active_threads',
'registers_per_thread', 'shared_memory_used',
'branch_efficiency', 'warp_execution_efficiency',
'memory_throughput', 'l2_hit_rate', 'dram_utilization'
],
'config': [
'ThreadDim.x', 'ThreadDim.y', 'ThreadDim.z',
'BlockDim.x', 'BlockDim.y', 'BlockDim.z',
'SharedMemSize', 'RegistersPerThread'
]
}
def load_benchmark_data(self, filepath):
"""Load and preprocess benchmark results"""
df = pd.read_csv(filepath)
# Add derived features
df['total_threads'] = (df['ThreadDim.x'] *
df['ThreadDim.y'] *
df['ThreadDim.z'])
df['block_size'] = (df['BlockDim.x'] *
df['BlockDim.y'] *
df['BlockDim.z'])
return df- Create Feature Matrices
class FeatureExtractor:
def prepare_feature_matrices(self, df):
"""Prepare X and Y matrices for modeling"""
X = {
'hardware': df[self.feature_groups['hardware']],
'kernel_stats': df[self.feature_groups['kernel_stats']],
'config': df[self.feature_groups['config']]
}
Y = df[['Power(W)', 'Time(s)', 'Energy(J)',
'GFLOPS', 'Bandwidth(GB/s)']]
# Normalize features
X_normalized = {}
for group, features in X.items():
X_normalized[group] = self.scaler.fit_transform(features)
return X_normalized, Y- Implement Statistical Analysis
class StatisticalAnalyzer:
def analyze_correlations(self, df):
"""Analyze feature correlations"""
corr_matrix = df.corr()
# Find important features for power
power_corr = abs(corr_matrix['Power(W)'])
perf_corr = abs(corr_matrix['GFLOPS'])
feature_importance = pd.DataFrame({
'power_corr': power_corr,
'perf_corr': perf_corr,
'combined_importance': power_corr + perf_corr
}).sort_values('combined_importance', ascending=False)
return feature_importance
def analyze_parameter_sensitivity(self, df):
"""Analyze parameter sensitivities"""
sensitivities = {}
for param in self.feature_groups['config']:
# Calculate gradient of power and performance
power_grad = np.gradient(df['Power(W)'], df[param])
perf_grad = np.gradient(df['GFLOPS'], df[param])
sensitivities[param] = {
'power_sensitivity': np.mean(np.abs(power_grad)),
'perf_sensitivity': np.mean(np.abs(perf_grad))
}
return sensitivities- Build Predictive Models
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
class PowerPerformanceModels:
def __init__(self):
self.power_model = RandomForestRegressor()
self.time_model = RandomForestRegressor()
def train_models(self, X, Y):
"""Train power and performance prediction models"""
# Combine feature matrices
X_combined = np.hstack([X[group] for group in X.keys()])
# Train power model
self.power_model.fit(X_combined, Y['Power(W)'])
power_scores = cross_val_score(self.power_model, X_combined,
Y['Power(W)'], cv=5)
# Train time model
self.time_model.fit(X_combined, Y['Time(s)'])
time_scores = cross_val_score(self.time_model, X_combined,
Y['Time(s)'], cv=5)
return {
'power_cv_scores': power_scores,
'time_cv_scores': time_scores
}- Implement Configuration Optimizer
class ConfigurationOptimizer:
def __init__(self, models, constraints):
self.models = models
self.constraints = constraints
def find_optimal_configs(self, df):
"""Find optimal configurations for different scenarios"""
optimal_configs = {
'energy_efficient': self._find_energy_efficient(df),
'high_performance': self._find_high_performance(df),
'balanced': self._find_balanced(df)
}
return optimal_configs
def _find_energy_efficient(self, df):
"""Find most energy-efficient configurations"""
valid_configs = df[
(df['Power(W)'] <= self.constraints['max_power']) &
(df['GFLOPS'] >= self.constraints['min_performance'])
]
return valid_configs.nlargest(5, 'EnergyEfficiency(GFLOPS/W)')- Main Analysis Pipeline
def main():
# Initialize components
processor = BenchmarkDataProcessor()
extractor = FeatureExtractor()
analyzer = StatisticalAnalyzer()
# Load and process data
df = processor.load_benchmark_data('benchmark_results.csv')
X, Y = extractor.prepare_feature_matrices(df)
# Perform statistical analysis
feature_importance = analyzer.analyze_correlations(df)
sensitivities = analyzer.analyze_parameter_sensitivity(df)
# Train models
models = PowerPerformanceModels()
cv_scores = models.train_models(X, Y)
# Find optimal configurations
constraints = {
'max_power': df['Power(W)'].max() * 0.9,
'min_performance': df['GFLOPS'].mean() * 0.8
}
optimizer = ConfigurationOptimizer(models, constraints)
optimal_configs = optimizer.find_optimal_configs(df)
# Generate reports
generate_analysis_report(
feature_importance,
sensitivities,
cv_scores,
optimal_configs
)To use this with your benchmark data:
- Save your benchmark results to a CSV file
- Modify the feature groups in
BenchmarkDataProcessorto match your data - Run the analysis pipeline
The analysis will provide:
- Feature importance rankings
- Parameter sensitivities
- Predictive model performance
- Optimal configurations for different scenarios
Would you like me to elaborate on any part of this implementation?
Q: Paper Presentation: Large language models are becoming larger and larger as we speak. Larger models means better performing models, but they also mean these models consume more and more energy, and as a result more and more CO2.
We want better AI models, but not at the cost of our planet. Which means we need to make AI models more energy efficient. To make AI energy efficient we can make the software more efficient, or the hardware more efficient. This is where we come into picture.
Our solution focuses on CUDA kernels - the fundamental building blocks of heavy computing AI workloads. We’ve discovered that kernel thread configurations strongly correlate with energy consumption, and this correlation varies by kernel type. Which means a given cuda kernel will behave different in term of energy consumption, depending on the shape or dimensions of threads it is executed in.
The second finding was that the degree of this correlation was dependent on the memory and compute intensity of the cuda kernels.
- Compute-Bound Kernels (like MATMUL):
- High arithmetic intensity (>2.0)
- Regular memory access patterns
- Achieved 28.5% energy reduction with only 0.25% performance impact
- Thread config: Maximizes x-dimension (256-1024 threads)
- Power limit: 125W baseline
- SM utilization improved by 197%
- Memory-Bound Kernels (like CONV):
- Moderate compute intensity (<0.5)
- Strided memory access
- Achieved 31.2% energy savings
- Thread config: Balanced x,y dimensions for 2D access
- Power limit: 100W baseline
- SM utilization improved by 25.8%
- Memory-Limited Kernels (like VECADD):
- Very low compute intensity (<0.2)
- Coalesced memory access
- 23.7% energy reduction
- Thread config: Maximized x-dimension for coalescing
- Power limit: 90W baseline
- Performance trade-off: -42.2%
- Irregular Kernels (like SPMV):
- Variable compute intensity
- Random memory access
- 1.3% energy reduction
- Thread config: Moderate for divergence management
- Power limit: 110W baseline
- Minimal performance impact: +0.15%”
So for a given cuda kernel, we can extract it’s shape, memory and compute metrics through static analysis of it’s source code like LLVM IR, and predict average power it would consume during its execution. Based on the the predicted power limit p of the GPU, we can change the GPU’s power limit to only let p watts of power to the GPU hardware, results in Delta E energy saving. Once we do this there will also be a tradeoff on the execution time of the kernel, depending on their category. We can let the user decide the tradeoff, and let the user choose what they want in terms of Energy and Speed tradeoff.
Methodology (1 minute): “Our approach uses static analysis to extract key features:
- Instruction mix and compute intensity
- Thread configuration and efficiency
- Memory access patterns and coalescing
- Hardware utilization metrics
Key correlations discovered:
- Z-dimension to Power: 0.54-0.78
- Time to Energy: 0.97-1.0
- Shape to Efficiency: 0.94-1.0”
Results and Impact (1 minute): “Overall achievements:
- 34% energy efficiency improvement
- Up to 197% hardware utilization gain
- Category-specific optimizations
- User-controllable performance-energy trade-offs
The system automatically:
- Categorizes kernels based on features
- Predicts optimal power limits
- Recommends thread configurations
- Adapts to user preferences for energy-performance balance”
- Static Analysis Features (LLVMAnalyzer):
- Instruction Mix:
- Arithmetic ops (add/sub/mul/div)
- Memory ops (load/store)
- Control ops (branch/call/return)
- Compute Intensity = arithmetic_ops / memory_ops
- Memory Access Patterns:
- Coalesced: Consecutive thread-based addressing
- Strided: Multiplication-based indexing
- Random: Other patterns
- Thread Configuration Features:
- Thread Dimensions: (x,y,z)
- x: 4-1024 (main parallelism)
- y: 1-32 (2D workloads)
- z: 1-16 (3D workloads)
- Block Dimensions: 1-1024³
- Total Threads = x * y * z
- Thread Efficiency = actual_threads / allocated_warps
- Memory Features:
- Access Types:
- Global: addrspace(1)
- Shared: addrspace(3)
- Local: addrspace(5)
- Coalescing Score = (coalesced_accesses) / total_accesses
- Bank Conflicts = strided_shared_memory_accesses
- Memory Efficiency = bandwidth_utilization / max_bandwidth
- Power Prediction Features:
power_components = {
'compute': {
'flops': measured_from_instructions,
'utilization': sm_activity / max_sms,
'weight': compute_intensity * 0.7
},
'memory': {
'bandwidth': memory_ops / time,
'pattern': coalescing_score,
'weight': memory_intensity * 0.3
}
}- Energy Calculation:
E_total = Σ[P_compute(t) + P_memory(t)] · Δt
where:
P_compute = α·FLOPS + β·Utilization
P_memory = γ·Bandwidth + δ·AccessPatternKey Correlations Found:
- Z-dimension → Power: 0.54-0.78
- Time → Energy: 0.97-1.0
- Shape → Efficiency: 0.94-1.0
This comprehensive feature set enables accurate power prediction and optimization.
Based on your research about CUDA kernel shapes and power optimization combined with the Zeus paper approach, here’s a suggested experimental study design:
- Study Setup & Hypothesis:
Primary Research Questions:
1. How do CUDA kernel shapes correlate with energy consumption?
2. Can we optimize power limits based on kernel shapes?
3. What's the trade-off between energy and performance for different shapes?
4. How do shape-energy relationships vary across kernel types?
- Experiment Design:
A. Kernel Categories to Test:
- Compute-bound (MATMUL)
- Memory-bound (CONV)
- Memory-limited (VECADD)
- Irregular access (SPMV)
B. Shape Parameters:
- Thread Dimensions (x,y,z): 4-1024, 1-32, 1-16
- Block Dimensions: 1-1024³
- Register usage
- Shared memory configuration
C. Power Settings:
- Range: From minimum to maximum allowed power limit
- Granularity: 25W steps
- Data Collection Pipeline:
A. Static Analysis:
- LLVM IR feature extraction
- Memory access pattern detection
- Compute intensity calculation
- Shape parameter extraction
B. Runtime Metrics:
- Energy consumption
- Execution time
- Power usage
- SM utilization
- Memory bandwidth
- Temperature
C. Per-Configuration Data:
- Shape parameters used
- Power limit set
- All runtime metrics
- Key Analyses to Perform:
1. Shape-Energy Correlation:
- Correlation between z-dimension and power
- Impact of thread/block ratio
- Effect of memory patterns
2. Performance Impact:
- Execution time vs shape parameters
- Memory throughput vs shapes
- SM utilization vs shapes
3. Energy Efficiency:
- Energy per operation
- Performance per watt
- Temperature impact
- Expected Outputs:
1. Visualization:
- Energy-Time Pareto curves per kernel type
- Shape-Energy correlation heatmaps
- Power scaling curves
2. Models:
- Shape-based power prediction
- Optimal shape recommendation
- Energy efficiency estimation
3. Guidelines:
- Shape selection strategies
- Power limit recommendations
- Shape-Power co-optimization
Would you like me to elaborate on any specific aspect of this experimental design?
General Guidelines
-
Thread Block Size
- Choose a multiple of 32 (warp size) for optimal performance[1][2].
- Common choices are 128, 256, or 512 threads per block[2][5].
- Avoid extremely small (<32) or large (>512) block sizes[6].
-
Grid Size
- Calculate based on your problem size and chosen block size[4].
- Ensure you launch enough blocks to cover your entire dataset.
Factors to Consider
Hardware Constraints
- Check your GPU’s limits using
cudaGetDeviceProperties[2]:- Max threads per block
- Max blocks per multiprocessor
- Number of multiprocessors
Occupancy
- Aim to maximize occupancy (active threads per SM)[1][5].
- Use CUDA’s occupancy calculator or runtime functions like
cudaOccupancyMaxPotentialBlockSize[5].
Problem Size
- Adjust grid size based on your data dimensions[4]:
dim3 block(32, 8, 4); dim3 grid((dimx+block.x-1)/block.x, (dimy+block.y-1)/block.y, (dimz+block.z-1)/block.z);
Kernel Characteristics
- Consider shared memory usage and register pressure[1].
- More complex kernels may benefit from smaller block sizes.
Optimization Process
-
Start with a Baseline
- Begin with 256 or 512 threads per block[6].
- Use
cudaOccupancyMaxPotentialBlockSizefor an initial estimate[5].
-
Profile and Benchmark
- Use CUDA profiling tools to measure performance.
- Experiment with different block sizes within the 128-512 range[2].
-
Fine-tune
- Adjust based on specific kernel requirements and GPU architecture.
- Consider using dynamic parallelism for complex problems.
-
Iterate
- Repeat the process for different input sizes and GPU models.
Example Calculation
const int problemSize = 1000000;
int threadsPerBlock = 256; // Starting point
int blocksPerGrid = (problemSize + threadsPerBlock - 1) / threadsPerBlock;
myKernel<<<blocksPerGrid, threadsPerBlock>>>(args...);there’s no one-size-fits-all solution. The optimal configuration often requires experimentation and is specific to your kernel, data size, and target GPU[1][2][6].
Citations: [1] https://stackoverflow.com/questions/4391162/cuda-determining-threads-per-block-blocks-per-grid [2] https://www.reddit.com/r/CUDA/comments/11sn3g6/maxing_out_the_device/ [3] https://docs.nvidia.com/cuda/cuda-c-best-practices-guide/ [4] https://forums.developer.nvidia.com/t/how-can-i-calculate-blocks-per-grid/248491 [5] https://stackoverflow.com/questions/9985912/how-do-i-choose-grid-and-block-dimensions-for-cuda-kernels/9986748 [6] https://forums.developer.nvidia.com/t/getting-the-best-performance/274000 [7] https://numba.pydata.org/numba-doc/dev/cuda/kernels.html